|
||||||||||||||||||
13Автоматизация Автоматизация наших задач — отдельное удовольствие. В какой еще профессии можно запрограммировать машины, чтобы они делали за нас нашу работу? Ах, если бы это было так просто! Автоматизация задачи требует времени, но выигрыш может быть огромным. Я не собираюсь здесь давать уроки Perl, Python, Ruby, UNIX shell, VBasic или Kix32. В этой главе я расскажу зачем, что и как следует автоматизировать. Кроме того, я приведу фрагменты кода, которые помогают мне в работе уже много лет. Достоинство автоматизации очевидно. Она сокращает нам объем работы, потому что автоматизированная задача требует от нас меньше внимания и времени или, благодаря «хрону» (cron) UNIX или планировщику Windows, выполняется автоматически, без нашего участия. Неожиданным положительным эффектом автоматизации является простота делегирования автоматизированной задачи. Любая задача, которую вы переложили на кого-то другого, уже является маленькой победой.
В этой главе терминами «сценарий» и «программа» я буду обозначать разные понятия. Сценарий — это короткая программа, возможно всего из нескольких строк. Типичным сценарием является ВАТ-файл, несколько строк на языке Perl или небольшой shell-файл UNIX. Программой я буду называть более длинные программы, разработка которых требует обдумывания и планирования. Как правило, формальный процесс создания программы включает сбор требований, разработку и тестирование. Программы обычно пишутся на компилируемых языках, таких как C++. Интерпретируемые языки, вроде Perl, тоже подходят для создания больших программ, но используются реже. Программисты, пишущие на языке Perl, называют свой код сценарием, если он невелик, и программой, если код имеет значительный объем.
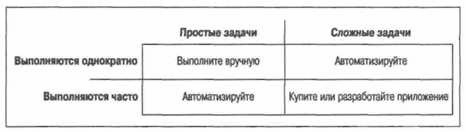
Что автоматизировать?Трудно найти время для автоматизирования процессов, поэтому приходится выбирать. Мы не можем автоматизировать всю нашу работу. Задачи, встающие перед системными администраторами, распадаются на четыре общие категории: • Простые задачи, выполняемые один раз. К первой категории относится большая часть вашей повседневной работы. Если задача проста и вы выполняете ее один раз, нет смысла ее автоматизировать. На автоматизацию уйдет больше времени, чем на саму задачу. • Сложные задачи, выполняемые один раз. Вторая категория включает задачи, достаточно сложные, чтобы выполнить их с первой попытки, поэтому, оформив последнюю (работающую) последовательность команд в виде сценария, вы получите инструкцию для ее следующего выполнения. Если вам понадобилось сделать что-то один раз, когда-нибудь придется делать это еще. Задачи этой категории состоят из длинных последовательностей команд, причем каждую команду лучше тестировать отдельно, постепенно строя цепочку из работающих команд. После этого вы сможете использовать эту последовательность с уверенностью, что она работает. • Простые задачи, выполняемые часто. Третья категория — очевидный случай, здесь отдача от автоматизации будет максимальной. Время, потраченное вами на автоматизацию процедуры, вскоре окупится, потому что вы будете выполнять задачу снова и снова. Всегда автоматизируйте скучные и повторяющиеся дела. • Сложные задачи, выполняемые часто. Четвертая категория — ловушка для системных администраторов, которые часто взваливают на себя больше, чем могут нести. Эта категория требует, чтобы вы убедили руководство в необходимости выделить ресурсы (время и деньги) на решение проблемы. Результатом может быть покупка коммерческого программного продукта, интеграция бесплатных инструментов и/или инструментов с открытым кодом в вашу систему или разработка собственного решения. Теперь, специально для читателей, мыслящих зрительными образами, приведу эти категории в виде таблицы (рис. 13.1).
Рис. 13.1. Категории задач системного администрирования Многие удивляются, узнав, что я автоматизирую простые, но часто выполняемые задачи. Если задача проста, зачем ее автоматизировать? Я автоматизирую многие процессы из второй и третьей категории — от крупных задач до небольших последовательностей команд — по одной причине. Автоматизация процесса придает ему повторяемость и масштабируемость, гарантируя выполнение без ошибок: • Повторяемость означает, что я могу многократно выполнять этот процесс. Например, устанавливая новые компьютеры, я хочу, чтобы все они запускались с одной конфигурацией программного обеспечения и с одинаковыми настройками. В противном случае обслуживание этих компьютеров превратится в кошмар. Если я автоматизирую процесс установки, он станет повторяемым, и все компьютеры будут иметь одинаковую конфигурацию. Если у меня какой-то процесс работает, я хочу, чтобы он каждый раз работал одинаково. Автоматизация избавляет меня от необходимости запоминать редко выполняемые сложные процессы. Иногда очень много времени уходит на выяснение опций командной строки, необходимых для выполнения поставленной задачи. Я превращаю в сценарий даже одиночную команду, чтобы через несколько месяцев мне не пришлось изобретать велосипед. Это, так сказать, долгосрочная повторяемость. Например, в Mac OS X я могу «прожечь» ISO-образ диска на CD-ROM с помощью команды hdutil. Однако вместо того чтобы читать руководство всякий раз, когда мне нужно вспомнить, какие опции подходят лучше всего, я инкапсулировал эту команду в сценарий. Теперь я всегда смогу использовать текст сценария для справки, даже не запуская его. • Масштабируемость. Это качество означает, что я смогу выполнить процесс независимо от того, как разрастется моя сеть. Автоматизировав процесс один раз, я смогу запускать сценарий на всех компьютерах, распространяя свое умение на все узлы сети. Например, очень легко изменить настройку конкретного SSH-сервера. Несколько секунд работы в текстовом редакторе, и файл sshd_config изменен. Однако если автоматизировать этот процесс, то я смогу запустить его на сотнях компьютеров, возможно, оставив его выполняться ночью. Мне не нужно будет присутствовать при его выполнении и волноваться о том, на скольких компьютерах он работает — на 10 или 10 000. • Автоматизация помогает избежать опечаток. Многие команды трудно ввести с клавиатуры без ошибок. Например, ту короткую последовательность команд, которую я постоянно использую. В нескольких строчках мне приходится трижды вводить имя пользователя и дважды — его учетный номер. Все это несложно набрать на клавиатуре, но довольно просто допустить опечатку. Превратив эту задачу в сценарий, я исключаю опечатки. Даже если надо ввести лишь несколько строк, имеет смысл создать сценарий. Процесс автоматизацииЧтобы что-то автоматизировать, сначала следует выполнить это вручную. Затем нужно написать код для каждого шага. После этого вы должны собрать эти фрагменты кода воедино, тестируя каждое добавление. В завершение необходимо протестировать всю систему. Шаг 1: выполнение процесса вручнуюПервый шаг при автоматизации процесса состоит в обязательном выполнении его вручную. Задокументируйте каждый шаг и убедитесь, что вы знаете, как закодировать его. Потом соберите все фрагменты кода. Один мой юный помощник постоянно подходил ко мне с просьбой помочь ему автоматизировать тот или иной процесс: «Я бьюсь над этой проблемой уже несколько часов! Я в тупике!» «О'кей,» — отвечаю я, — «Покажи, как ты это делаешь вручную». «Я не знаю. Мне не удалось это выяснить». «Вот в этом твоя главная проблема, балбес. Понял?» Как было сказано в главе 12, одним из плюсов документирования является то, что запись шагов процесса позволяет вам впоследствии автоматизировать его. Я не шучу. Если у меня нет времени автоматизировать какую-то задачу, я привожу ее поэтапное описание на своем Wiki-сайте и поручаю кому-нибудь ее выполнить. Тем самым я достигаю сразу две цели. Во-первых, я расширяю документацию, описывающую работу нашей системы. Во-вторых, я делаю первый шаг на пути автоматизации этой задачи! ♥ Документируйте все шаги процесса, а затем автоматизируйте их. Если вы не в состоянии записать шаги, вы никогда не сможете автоматизировать их. Запись процесса уже вынуждает вас идентифицировать все его этапы. Вместо того чтобы держать их в голове, вы покажете документ другим, и они смогут проверить его на практике. Если у вас нет Wiki-сайта, воспользуйтесь ручкой и бумагой или текстовым файлом. Выполняйте процесс вручную и записывайте, что вы делаете. Каждую введенную вами команду следует включить в документ. Шаг 2: кодирование каждого шагаПреобразуйте каждый шаг в команду или короткую программу. Протестируйте каждый шаг отдельно. Иными словами, напишите несколько маленьких сценариев, каждый из которых позволит убедиться, что код для соответствующего шага верен. Если на каком-то шаге вы используете графический пользовательский интерфейс, необходимо найти его эквивалент в виде последовательности команд. В некоторых операционных системах это просто. Например, в SAM (System Administration Manager, диспетчер системного администрирования) из HP-UX есть кнопка, позволяющая отобразить команду операции, которую диспетчер выполнит следующей. В Mac OS X есть Automator и AppleScript, позволяющие автоматизировать операции, выполняемые с помощью графического интерфейса. Для Windows есть множество аналогичных утилит. Однако инструменты, автоматизирующие щелчки по кнопкам, могут оказаться менее эффективны, чем непосредственная установка ключей реестра или записей LDAP. Рекомендуемая литература для администраторов Microsoft Windows: • «Windows Server Cookbook» (Сервер Windows. Сборник рецептов), O'Reilly. Прочитав ее от корки до корки, вы узнаете массу полезных вещей. Вас удивит, как много операций, которые вы привыкли выполнять с помощью графического интерфейса, может быть записано в виде сценариев путем несложного редактирования реестра. Эта книга откроет вам глаза на многое. Примеры приводятся на нескольких языках, как правило на VBasic и Perl. • «Perl for System Administration», O'Reilly.[4] Эта книга особенно пригодится тем, кто работает и в UNIX, и в Windows. Как следует из названия, основное внимание в ней уделено языку Perl, и люди с опытом работы в Enterprise или UNIX с легкостью осилят ее. Кроме того, она будет полезна тем, кто много работает с ActiveDirectory и/или LDAP. • «Win32 Perl Scripting: The Administrator's Handbook» (Создание сценариев на Perl для Win32. Справочник системного администратора), Sams. Тоже весьма полезная книга, особенно если вы только начинаете писать сценарии. Рекомендуемые книги для администраторов UNIX/Linux: • «Perl for System Administration» (см. выше). • «UNIX System Administration Handbook»,[5] Prentice Hall PTR. Эта книга не только учит вас основам системного администрирования в UNIX, но и содержит много полезных ссылок и инструментов. В большинстве примеров приводится командная строка, что облегчит написание сценариев. • «Essential System Administration» (Основы системного администрирования), O'Reilly. Еще одна великолепная книга с примерами, в которых используется командная строка. • «Advanced Bash-Scripting Guide» (Расширенное руководство по написанию скриптов bash). Посетите сайт http://www.tldp.org/gui-des.html. Шаг 3: сборка шагов воединоЕсли код каждого шага работает, вы можете собрать все фрагменты в один сценарий. При сборке кода все-таки лучше добавлять по одному шагу за раз. Тестируйте код после каждого добавления. Такой подход называется итеративной разработкой и является оптимальным при автоматизации. Тестируя сценарий после каждого добавления, вы в большей степени уверены, что вся конструкция работает, как задумано. Например, когда на работу приходит новый сотрудник, нужно создать для него запись в каталоге LDAP, выделить ему место на внутреннем веб-сервере и протестировать его учетную запись, чтобы убедиться в ее корректности. Каждое из этих действий может быть автоматизировано само по себе. Убедитесь, что команды, выполняемые на каждом шаге, работают. Затем соберите первую группу команд в сценарий и протестируйте его. Убедитесь, что последовательность команд работает и выводится необходимая вам отладочная информация. Запустите сценарий и убедитесь в корректности записей LDAP. Если все работает, добавьте следующую группу команд и протестируйте, что получилось. Убедитесь, что записи LDAP по-прежнему корректны и что пространство на внутреннем веб-сервере выделено. Добавьте еще одну группу команд и снова все проверьте. Шаг 4: тестирование всего процессаНаконец, мы должны протестировать процесс в целом. Если мы тестировали его после добавления каждого шага, тут будет совсем немного работы. Вообще-то программисты не любят тестировать. Им хочется, чтобы программа правильно работала с первого запуска. Если выполнять тестирование на каждом шаге, оно не выглядит особо трудоемким; в результате на последней стадии приходится делать не так уж много. Простые задачи, выполняемые частоПриведу несколько примеров часто выполняемых простых задач. Обращаю внимание системных администраторов Windows, что эти примеры ориентированы на UNIX/Linux. Тем не менее, общие принципы применимы ко всем операционным системам. Сокращения для командБольшинство систем с командной строкой имеет ту или иную возможность создания псевдонимов. Это позволяет вам создавать новые команды на основе существующих. В каждой операционной системе принят свой синтаксис. В системе UNIX имеется множество языков оболочки (командной строки), самыми популярными из которых являются bash и csh. Они сильно различаются, и вы заметите, что, в первую очередь, в bash приходится употреблять знак равенства. Я приведу примеры для обеих оболочек. ♥ Примеры на bash будут работать в любой оболочке, смоделированной по оригинальной Bourne Shell, созданной Стивом Борном (Steve Bourne) (/bin/sh), например в Korn Shell (/bin/ksh) и Z Shell (/bin/zsh). Аналогичным образом примеры на csh будут работать в любой оболочке, имеющей корни csh, включая оболочку Tenex С shell (/bin/tcsh). Как попасть в нужный каталог Мне нередко приходится выдавать команду cd для перехода в каталог с очень длинным путем. Вот пример использования псевдонима: bash: alias book='cd "tal/projects/books/time/chapters' csh: alias book 'cd "tal/projects/books/time/chapters' Теперь я могу набирать на клавиатуре book каждый раз, когда мне нужно перейти в каталог, где находятся файлы для текущей книги. Если я возьмусь написать другую книгу, я обновлю этот псевдоним. (Я ввожу «book» в течение последних шести лет!) Это не только позволяет сэкономить на вводе. Вы избавлены от необходимости запоминать путь к каталогу. Освободить свою память всегда полезно. Чтобы сделать псевдоним постоянным, вы должны добавить указанную строку в файл .profile, bashrc (bash) или .cshrc (csh). Эти файлы считываются только во время входа в систему, так что либо выйдите из системы и войдите обратно, либо введите команду source, чтобы файлы были прочитаны снова. bash: . "/.profile csh: source "/.cshrc (Примечание: в bash эта команда обозначается точкой.) Псевдоним может обозначать целую последовательность команд. Отделяйте их друг от друга точкой с запятой. Вот пример, где выполняется переход в некоторый каталог и устанавливается переменная окружения в зависимости от того, работаем мы в системе А или В: bash: alias inva='cd "tal/projects/inventory/groupa; export INVSTYLE=A' alias invb='cd "tal/projects/inventory/groupb; export INV3TYLE=B' csh: alias inva 'cd "tal/projects/inventory/groupa; setenv INVSTYLE A' alias invb 'cd "tal/projects/inventory/groupb; seteiw INVSTYLE B' Вместо точки с запятой можно поставить двойной амперсанд для обозначения такого условия: «Выполнить следующую команду только в том случае, если первая завершилась удачно». Этот прием полезен, если нужно избежать выполнения команды не в том каталоге. Например, вы хотите перейти в некоторый каталог и поставить там метку времени в журнале. Однако если команда cd не будет выполнена (сервер недоступен), не следует ставить метку времени в журнале текущего каталога. bash; alias rank='cd /home/rank/data && date». log' csh: alias rank 'cd /home/rank/data && date». log' ♠ Не пытайтесь превратить одну операционную систему в другую. Псевдонимы сами по себе хороши, но ими нельзя злоупотреблять. Я часто видел людей, создающих десятки псевдонимов для того, чтобы симулировать DOS в UNIX. Думаю, это плохая идея. Так вы никогда не научитесь работать в UNIX, а, оказавшись за чужим компьютером, где нет ваших псевдонимов, попадете впросак. Сокращения для имен компьютеров Если вам приходится снова и снова вводить имена каких-то компьютеров, вы можете сэкономить немного времени, создав псевдонимы. Например, если вы часто обращаетесь к серверу ramanujan.company.com, то можете создать псевдоним (запись DNS CNAME) ram.company.com. Это имя чуть проще набирать на клавиатуре. Проблема, связанная с таким подходом, заключается в том, что он может превратить сопровождение в кошмар. Если пользователи станут употреблять оба имени, вам придется сопровождать два имени. Вопрос: как бы создать псевдоним, известный только вам, не беспокоя других пользователей? Как правило, часто обращаясь к какому-то серверу, я почти во всех случаях использую SSH (Secure SHell). Это безопасная (криптографически защищенная) альтернатива telnet и rsh. С ее помощью вы также можете копировать файлы (вводя scp вместо гср), и многие программы, например rsync, работают с SSH. Система Unix SSH (OpenSSH и ее сестры) позволяет вам установить псевдонимы, известные всем пользователям UNIX, либо псевдонимы, доступные только вам. Чтобы ограничиться только своими SSH-сеансами, добавьте псевдонимы в файл ~/.ssh/config. Если же вы хотите предоставить псевдонимы в распоряжение всех пользователей, добавьте псевдонимы в файл /etc/ssh_config или /etc/ssh/ssh_config в зависимости от конфигурации вашей системы. В следующем примере я создаю псевдоним es, чтобы избавить себя от необходимости вводить www.everythingsysadmin.com: Host es HostName www.everythingsysadmin.com Теперь я могу не только вводить ssh es вместо ssh www.everythingsysadmin.com, но и использовать этот псевдоним в командах scp, sftp, rsync и других. Более того, сценарии и программы, которые я не могу изменить, будут автоматически воспринимать новые настройки. Вот несколько примеров: $ ssh es $ scp file.txt es:/tmp/ $ rsync ex:/home/project/alpha "/project/alpha Я использую ssh es так часто, что создал псевдоним на уровне оболочки: bash: alias es='ssh es' csh: alias es 'ssh es' В результате теперь я могу вводить в командной строке es, чтобы войти в систему, или с помощью всех тех же двух букв обозначить хост в командах scp или rsync. Ведь круто? Возникает соблазн создать двухбуквенные псевдонимы для всех серверов на свете. Однако вскоре вы обнаружите, что вспоминаете обозначения дольше, чем вводите имена с клавиатуры. Я ограничил себя несколькими серверами, к которым обращаюсь через SSH. На странице ssh_config(5) справочной системы man перечислено много других опций конфигурации. Например, иногда я обращаюсь к серверу, для которого требуется весьма специфическая комбинация опций в командной строке. (Это доморощенная версия SSH-сервера, которая не только не обладает всеми функциональными возможностями, но просто отказывается работать, получая строку, которую не понимает.) Команда, которую я должен ввести, выглядит так: $ ssh — х -о RSAAuthentication=yes — о PasswordAuthentication=yes — о ChallengeResponseAuthentication=no -1 peter.example.net Я мог бы установить псевдоним, но вместо этого изменил конфигурацию SSH, и все системы, использующие SSH, работают, как надо. Если сценарий, который я не могу изменить, использует SSH для доступа к тому серверу, он воспримет эти настройки. Соответствующие строки в моем файле ~/.ssh/config выглядят так: Host peter.example.net ForwardX11 no RSAAuthentication yes PasswordAuthentication yes ChallengeResponseAuthentication no Compression no Protocol 1 У SSH-клиентов для Windows обычно есть графический интерфейс, позволяющий сохранить настройки профиля, которые следует использовать для конкретного сервера (или нескольких серверов). Чем больше вы знаете про SSH, тем больше вы можете сделать. Есть много хороших книг и электронных справочников с подробным описанием SSH, например «SSH, The Secure Shell: The Definitive Guide» (SSH. Безопасная оболочка: полное руководство), O'Reilly. Если в SSH и есть то, что должен знать каждый системный администратор (но, возможно, не знает), то это следующее: как настроить открытые/закрытые (public/private) ключи, чтобы, не снижая уровень безопасности, исключить необходимость ввода пароля при обращении с одного конкретного компьютера к другому через SSH. Make-файл для каждого хостаЭтот раздел относится исключительно к системам UNIX/Linux. Тот, кто работает в Windows, может его пропустить. В системах UNIX/Linux важная информация часто хранится в обычных текстовых файлах, которые можно отредактировать вручную. В некоторых случаях после редактирования файла необходимо выполнить специальную команду, чтобы сообщить системе, что информация изменилась. Например, после редактирования файла /etc/aliases (к которому обращаются sendmail, Postfix и различные пакеты пересылки почты), вы должны выполнить команду newaliases. Ее легко запомнить, не так ли? А какую команду надо выполнить после редактирования файла transports программы Postfix? Возможно, newtransports? Нет, это было бы слишком просто. Вы должны выполнить postmap transports. А еще есть команда т4, которую нужно выполнить после редактирования m4-файлов и т. д., и т. п.
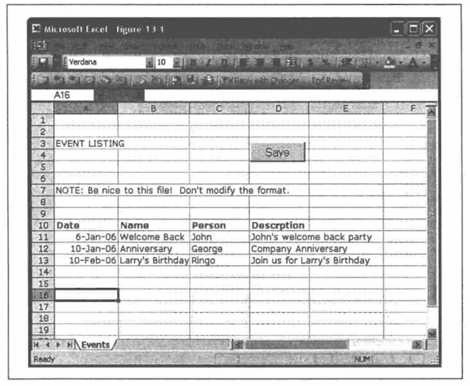
У кого найдется время заучить все команды, которые нужно выполнить после редактирования файлов? Такие подробности должен помнить сам компьютер. На помощь приходит команда make! Вы можете считать ее программным инструментом, чем-то вроде компилятора. Она позволяет вам указать, какую команду нужно запускать для обновления одного файла, если в другой были внесены изменения. ♥ Команда make является одним из самых мощных инструментов системного администрирования, которые когда-либо были изобретены. Я слышал, что программисты тоже считают ее полезной! У команды make больше функциональных возможностей, чем было мужей у Элизабет Тейлор, поэтому я лишь вкратце представлю ее вам. (Прочитав только первые две главы практически любой книги, посвященной команде make, вы узнаете 99 % того, что необходимо для большинства задач системного администрирования, и в 10 раз больше, чем знают коллеги.) Краткое описание команды makeКоманда make читает файл конфигурации, весьма уместно именуемый Makefile. В этом файле находятся инструкции, которые сообщают команде make, что она должна делать. Каждая инструкция имеет такой формат: whole: partA partB partC команда, создающая whole Инструкция начинается с имени файла, который должен быть создан. Затем стоит двоеточие, после которого указаны файлы, необходимые для построения главного.[6] В этом примере создается файл whole, и устанавливается соотношение между partA, partB и partC. Если один из них будет отредактирован, мы должны будем выполнить команду, создающую whole. Приведу вполне реальный пример: aliases.db: aliases newaliases @echo Done updating aliases Этот код означает, что, если файл aliases будет изменен, команда newaliases регенерирует файл aliases.db. В случае успеха будет выведено сообщение «Done updating aliases» (Выполнено обновление aliases). Обратите внимание на то, что вторая и третья строчки кода написаны с отступом. Отступ обязательно достигается табуляцией, а не последовательностью пробелов. Почему? Наверное, создатель команды make хотел наказать меня за каждую попытку скопировать участок кода в системе, преобразующей табуляцию в пробелы. Впрочем, я не принимаю это на свой счет. Обновление файла не происходит автоматически. Вы должны только запустить команду make: Server1# make aliases.db newaliases Done updating aliases Server1# Вот так! Команда make прочитала свой файл конфигурации, выяснила, что файл aliases новее, чем aliases.db (сравнив их метки времени), и определила, что запуск команды newaliases приведет к обновлению файла aliasesAb. Попробуем запустить make еще раз: Server1# make aliases.db Server1# Сообщение об обновлении не выводится. Почему? Потому что теперь согласно меткам времени ничего делать не нужно, ведь файл aliases.db новее файла aliases. Команда make ленива и выполняет минимум работы, необходимый для получения результата. Она принимает решения на основе меток времени в файлах. Вот еще один пример кода в файле Makefile: file1.output: file1.input command1 <file.input> file.output file2.output: file2.input command1 file2.input >$@ В первом случае команда, которую следует выполнить, использует стандартные потоки ввода/вывода stdin и stdout (перенаправление обозначено символами < и >), чтобы прочитать fileXnput и произвести запись в file, output. Второй фрагмент аналогичен первому, но команда берет имя входного из командной строки и перенаправляет вывод… куда? Конструкция $@ означает «файл, создаваемый этой инструкцией», в нашем случае это file2.output. Почему не придумали мнемоническое обозначение, вроде $the или $this? Неизвестно. Вам совсем не обязательно использовать обозначение $@, но с ним вы будете выглядеть умнее своих коллег. Команда make, запущенная без параметров, выполняет первую инструкцию из файла Makefile. По традиции первая инструкция называется all, и она выполняет все инструкции, которые должны быть выполнены по умолчанию. Таким образом, запуск make выполняет все важные инструкции. Возможно, это будут не все инструкции, а лишь те, которые вы хотите выполнить по умолчанию. Эта инструкция может выглядеть, например, так: all: aliases.db access.db Команда make без параметров проверяет, не обновлялись ли файлы aliases.db и access.db. Поскольку в инструкции all не указано никакой команды, файл с именем all создан не будет. Тогда make будет считать, что файл all устарел («не существует» эквивалентно «устарел»). Вскоре вы поймете важность такой интерпретации. Не будем забывать, что команда make ленива. Если файл access.db устарел, а второй файл — нет, то она выполнит только действия по обновлению access.db. Если для обновления файла потребуются какие-то дополнительные действия, а для них что-то еще, то команда make рационально выполнит только необходимый минимум работы. Кроме инструкции all, я обычно пишу еще пару-тройку полезных команд: reload: postfix reload stop: postfix stop Start: postfix start Обсудим, что они означают. Если я введу make reload, команда make заметит отсутствие файла reload и запустит команду postfix reload в надежде, что та создаст такой файл. Ага! Я ее перехитрил! Указанная команда перегружает конфигурацию Postfix. Она не создает никакого файла reload Когда я выполню make reload в следующий раз, команда make поступит точно так же. Другими словами, если вы хотите, чтобы некоторое действие выполнялось всегда, сделайте так, чтобы инструкция не создавала файл, который надеется создать команда make. Имея код, приведенный выше, я могу перезагрузить, остановить и запустить postfix, введя команду make reload, make stop и make start соответственно. Если есть другие процессы, которые требуется остановить (например, IMAP сервер, веб-клиент электронной почты и т. д.), я включу необходимые команды в инструкции. Мне не нужно запоминать эти команды. Сейчас я должен признать, что раньше чуть-чуть передернул. Я сказал, что каждая инструкция начинается с имени файла, который нужно создать, затем идет двоеточие, а затем — список файлов, образующих главный. Так вот, команде make неизвестно, состоит ли в действительности создаваемый файл из перечисленных. У нее нет способа проверить это. Элементы, указанные после двоеточия, являются всего лишь параметрами, которые не должны быть устаревшими. Приведу простой пример реального файла Makefile, который запускает Postfix и содержит инструкции обновления индекса для файлов aliases и access. В начале файла вы заметите константы (NEWALISES, PDIR и т. д.), используемые далее в файле. Обратный слэш (\) в конце строки кода служит для переноса длинных строк: NEWALISES=/usr/sbin/newaliases PDIR=/etc/postfix POSTMAP=/usr/local/postfix/sbin/postmap # Команды all: $(PDIR)/aliases.pag $(PDTR)/aliases.dir \ $(PDIP)/access.dir $(PDIR)/access.pag reload reload: postfix reload stop: postfix stop start: postfix start # # Когда aliases изменится, сгенерировать файлы. pag and.dir # $(PDIR)/aliases.pag $(PDIR)/aliases.dir: $(PDIR)/aliases $(NEWALIASES) # # Когда access изменится, сгенерировать файлы. pag and.dir # $(PDIR)/access.dir $(PDIR)/access.pag: $(PDIR)/access $(POSTMAP) $(PDIR)/access Теперь я могу отредактировать файл aliases или access и ввести команду make. Мне не нужно помнить, что команды обновления индексов сильно различаются. Я не должен помнить о необходимости перезагружать конфигурацию Postfix, потому что соответствующая команда включена в инструкцию all. Конструкция reload в конце all будет каждый раз запускать эту инструкцию. С помощью команды make можно также поддерживать свежие версии файлов на разных серверах. Предположим, что на обоих наших почтовых серверах файлы aliases должны быть одинаковыми. Мы решаем отредактировать файл на одном сервере и скопировать его на сервер server2. Инструкция может выглядеть, например, так: push.aliases.done: $(PDIR)/aliases scp $(PDIR)/aliases server2:$(PDIR)/aliases touch $@ Мы копируем файл на serveг2 командой scp, затем применяем команду touch к файлу push.aliases.done. Поскольку этот файл создается после успешной операции копирования, мы можем построить инструкции так, что копирование будет выполняться только в случае необходимости. Мы также можем принудительно скопировать файл, если просто удалим push.aliases.done и введем команду make. Традиционно вводится инструкция clean, которая удаляет все файлы *.done и прочие файлы, сгенерированные автоматически. В файлах, имена которых оканчиваются на .done, нет ничего особенного. Это обычные файлы с меткой времени или флагом для имени. Рассмотрим развернутый пример. Имеются два файла, подлежащие индексации после редактирования: aliases и access. Если хотя бы один из них проиндексирован заново, выдается команда перезагрузки Postfix. Кроме того, оба файла копируются на serveг2, если они были изменены. Наконец, команда cd /etc && make выполняется на server2 тогда и только тогда, когда на него был скопирован хотя бы один файл. Будьте внимательны, создавая инструкции. Правильно указывайте параметры и применяйте команду touch к файлам *.done, если потребуется. Команда make выполнит лишь минимум работы, необходимый для обновления системы. # # Makefile для server1 # NEWALISES=/usr/sbin/newaliases PDIR=/etc/postfix POSTMAP=/usr/lосаl/postfix/sbin/postmap # # "Команды" высокого уровня # all: aliases.done access.done reload_if_needed.done push push: push.done reload: postfix reload stop: postfix stop start: postfix start reload_if_needed.done: aliases.done access.done postfix reload touch reload_if_needed.done clean: rm — f \ $(PDIR)/aliases.pag $(PDIR)/aliases.dir \ $(PDIR)/access.dir $(PDIR)/access.pag \ push.aliases.done push.access.done \ reload_if_needed.done # # Инструкции для конкретных файлов, # которым требуется индексация/регенерация # # Если aliases изменится, сгенерировать файлы. pag and.dir aliases.done: $(PDIR)/aliases.pag $(PDIR)/aliases.dir $(PDIR)/aliases.pag $(PDIR)/aliases.dir: $(PDIR)/aliases $(NEWALIASES) # Если access изменится, сгенерировать файлы. pag and.dir access.done: $(PDIR)/access.dir $(PDIR)/access.pag $(PDIR)/access.dir $(PDIR)/access.pag: $(PDIR)/access $(POSTMAP) $(PDIR)/access # # Копирование # push.done: push.aliases.done push.access.done ssh server2 "cd /etc && make" touch $@ push.aliases.done: aliases.done scp $(PDIR)/aliases server2:$(PDIR)/aliases touch $@ push.access.done: access.done scp $(PDIR)/access server2:$(PDIR)/access touch $@ Этот Makefile является для вас хорошей стартовой площадкой. Он довольно сложен, потому что нам нужна гарантия того, что Postfix перезагрузится, лишь когда это абсолютно необходимо. Такой Makefile избавляет вас от необходимости помнить множество команд, в том числе те, которые необходимы для обновления конкретных файлов. Вы больше не боитесь забыть какую-то команду. Многие сложные процедуры теперь сводятся к двум шагам: 1. Отредактировать нужный файл. 2. Ввести команду make. Команда make является универсальным инструментом для соединения нескольких автоматизированных процессов. Однажды я должен был объединить несколько процессов и процедур для трех больших сетей. В каждой сети была своя система сопровождения псевдонимов, хостов и прочей административной информации. Разобравшись в процедурах для каждой сети, я построил Makefile для главных серверов этих сетей. Имена инструкций верхнего уровня были одинаковыми для всех трех сетей, но команды, которые они выполняли, для каждой сети были свои. В мои стратегические планы входило создание нового главного сервера, который в конечном счете заменил бы все серверы, доставшиеся мне, так сказать, в наследство. Первоначально Makefile нового главного сервера просто вызывал команду make на трех главных серверах с помощью команды rsh (это было задолго до появления ssh). Затем я поочередно перенес инструкции на новый сервер. Вначале я решил, что новый главный сервер должен быть единственным источником информации для файла aliases. Я слил файлы aliases всех трех сетей и разместил результат на главном сервере. Протестировав его, я создал инструкции, которые копировали этот объединенный файл на прежние главные серверы так, словно это был их собственный файл. Я поступил аналогичным образом с каждым файлом и каждой базой данных. Поскольку каждое изменение было незначительным и конкретным, я мог выполнять тестирование итеративно. Произведя буквально несколько сотен изменений, я добился того, что все серверы «пели в унисон». В этот момент мне не составило труда исключить старые главные серверы и поставить новый над всеми клиентами. ♠ Любой файл, автоматически копируемый на другие серверы, должен обязательно содержать в начале комментарий, информирующий других системных администраторов, откуда файл пришел и где его следует редактировать. Вот комментарий, который я пишу: # ЭТОТ ФАЙЛ СОПРОВОЖДАЕТСЯ НА СЕРВЕРЕ: # server1.example.com # Редактируйте его при помощи команды: xed file.txt # Если вы отредактируете его на любом другом компьютере, # он будет перезагружен. БУДЬТЕ ВНИМАТЕЛЬНЫ! Поскольку в комментарии упоминается xed, я должен пояснить, что это такое. Есть несколько программ с именем xed, но эту конкретную программу можно найти по адресу http://www.nightcoder.com/code/xed. Она вызывает редактор, которым вы обычно пользуетесь ($EDITOR можно установить в vi, pico, emacs и т. д.), после того как заблокирует файл. Это обязательное условие для любого сайта, на котором один компьютер используют несколько системных администраторов. Если вы отслеживаете изменения в файле с помощью RCS, эта система зарегистрирует все попытки отредактировать файл. Вы получаете практически бесконечный откат и журнал, где записано, кто и что изменил. Если вы заметите, что последний месяц система ведет себя как-то странно, то проверьте, кто редактировал файл месяц назад. Будьте снисходительны: все мы допускаем ошибки. Сложные задачи, выполняемые однократноАвтоматизация работы предполагает, что, выполняя нечто сложное, мы записываем последовательность действий. В этом случае повторить действия впоследствии много проще. Это как если бы мы строили для себя некоторую подстраховку. Инкапсуляция сложной командыБывает, что на создание команды, которая делает именно то, что нужно, уходит несколько часов. Например, есть программа, создающая ISO-образы диска для последующей записи на CD-ROM. На странице ее описания перечислены сотни параметров, но команда, позволяющая создать образ, читаемый в Windows, UNIX и Mac OS X, достаточно проста: $ mkisofs — D -l — J -r — L -f — P "Имя автора" — V "метка диска" — copyright \ copyright.txt — о disk.iso /directory/of/files Конечно, все можно проделать с помощью графического интерфейса, но вы не получите никакого удовольствия (а также возможности создать сценарий). Эта команда позволяет вам делать то, что недоступно в большинстве графических интерфейсов, например сообщать об авторских правах, указывать имя автора и т. д. Она хорошо встраивается в JJAT-файл (в DOS) или в сценарий оболочки UNIX/Linux. Вот пример сценария makeimage1, в котором используется эта команда: #!/bin/bash mkisofs — D -l — J -r — L -f — P "Limoncelli" — V 'date — u +%m%d' $* Конструкция 'date — u +%m%d' создает метку тома, содержащую текущую дату. Я долго не мог создавать хорошие сценарии, потому что не знал, как обрабатывать параметры командной строки. Расскажу, как следует копировать их в сценарий. Конструкция $* в сценарии означает «любые элементы командной строки». Если вы введете: $ makeimage1 cdrom/ то последовательность $* будет заменена на cdrom/. Поскольку $* работает и с несколькими аргументами, вы можете ввести: $ makeimage1 cdrom/ dir1/ dir2/ В этом случае вместо $* будут подставлены все три аргумента. Команда mkisofs сольет (merge) все три каталога на CD-ROM. Если вы хотите указать конкретные элементы командной строки, пишите $1, $2 и т. д. В нашем примере $1 будет соответствовать cdrom/, а $2 — dir1/. Еще одной причиной, не позволявшей мне писать хорошие сценарии, было мое неумение обрабатывать флаги командной строки, например scriptname — q file1.txt. Если сценарий, который требовалось написать, был настолько сложен, что требовал учета флагов командной строки, я использовал другой язык или вообще отказывался от создания сценария. Оказывается, в bash есть функция getopt, которая выполняет синтаксический разбор. Однако руководство по bash написано не совсем понятно. В нем сказано, как работает getopt, но не объясняется, как пользоваться этой функцией. Наконец, я нашел подходящий пример и с тех пор периодически копирую его. Неважно, как он работает. Чтобы воспользоваться им, вам совсем необязательно понимать, что он делает и почему. А выглядит он так: args='getopt ab: $*' if [$?!= 0] then echo "Usage; command [-a] [-b file.txt] file1 file2…" exit -1 fi set — $args for i do case "$i" in -a) FLAGA=1 shift ;; -b) ITEMB="$2"; shift shift ;; -) shift; break ;; esac done Предполагается, что есть некая команда с флагами — а и — b. Второй флаг особый, потому что за ним должен следовать аргумент, например — b file.txt. Из первой строчки понятно, что за командой getopt следуют буквы, которые могут быть флагами. После флага, которому требуется дополнительный аргумент, стоит двоеточие. Далее мы видим оператор case (выбор) для каждого возможного аргумента. Код оператора либо устанавливает флаг, либо устанавливает флаг и сохраняет аргумент. А что такое $2? И какой смысл в — )? И что делает set? И как поживает Наоми? Все это вы сможете узнать потом. А сейчас воспользуйтесь образцом, и он будет работать. (Ну ладно. Если вы вправду хотите в этом разобраться, прочитайте «Advanced Bash-Scripting Guide» (Расширенное руководство по написанию скриптов bash) по адресу http://www.tldp.org/LDP/abs/html.) Теперь я приведу более развернутый пример, иллюстрирующий некоторые дополнительные возможности. Во-первых, в нем определяется функция usage, предназначенная для вывода справочной информации. Интересная особенность этой функции — команда echo, растянутая на несколько строк. Неплохо, не так ли? bash не возражает. Во-вторых, в этом сценарии проверяется наличие минимального количества (MINITEMS) элементов командной строки после обработки аргументов. Наконец, сценарий демонстрирует обработку флагов, переопределяющих умолчания. Пожалуйста, пользуйтесь этим кодом, если вам понадобится преобразовать простой сценарий в сценарий, обрабатывающий параметры и флаги: #!/bin/bash MINITEMS=1 function usage { echo " Usage: $0 [-d] [-a author] [-c file.txt] [-h] dir1 [dir1…] -d debug, don't actual run command -a author name of the author -c copyright override default copyright file -h this help message " exit 1 } # Задание умолчаний: DEBUG=false DEBUGCMD= AUTHOR= COPYRIGHT=copyright.txt # Обработка аргументов командной строки # с возможным переопределением умолчаний args='getopt da: c:h $*' if [$?!= 0] then usage fi set — $args for i do case "$i" in -h) usage shift ;; -a) AUTHOR="$2"; shift shift ;; -c) COPYRIGHT="$2"; shift shift ;; -d) DEBUG=true shift ;; -) shift; break;; esac done if $DEBUG; then echo DEBUG MODE ENABLED. DEBUGCMD=echo fi # Проверка наличия минимального количества элементов # командной строки if $DEBUG; then echo ITEM COUNT = $#; fi if [$# — lt "$MINITEMS"]; then usage fi # Если первый аргумент особый, запомнить его: # ТНЕIТЕМ="$1"; shift # Клонируйте эту строчку для каждого элемента, # который хотите сохранить. # Не забудьте при этом откорректировать значение # переменной MINITEMS. # Если вы хотите обработать остальные элементы, # делайте это здесь: # for i in $*; do # echo Looky! Looky! I got $i # done if [! -z "$COPYRIGHT"]; then if $DEBUG; then echo Setting copyright to: $COPYRIGHT; fi CRFLAG="-copyright $COPYRIGHT" fi LABEL='date — u +%Y%m%d' $DEBUGCMD mkisofs — D -l — J -r — L -f — P "$AUTHOR" — V $LABEL $CRFLAG $*Построение длинной командной строки Самый лучший способ научиться сцеплять команды UNIX/Linux в один длинный канал — заглядывать через плечо того, кто этим занимается. Сейчас я попробую научить вас делать это, создав на ваших глазах небольшую утилиту. ♥ Книга «Think UNIX» (Думайте в духе UNIX), Que, — отличный учебник по объединению инструментов UNIX/Linux в длинные команды. Самой мощной технологией, представленной в UNIX/Linux, является возможность объединить несколько команд аналогично тому, как наращивают садовый шланг для поливки. Если у вас есть программа, которая преобразует входной текст в верхний регистр, и программа, сортирующая строки в файле, то вы можете сцепить их друг с другом. В результате вы получите команду для преобразования строк в верхний регистр и их вывода в заданном порядке. Все, что от вас требуется, — это поставить символ «|» между командами. Выходная информация одной команды поступит на вход следующей: $ cat файл | toupper | sort Тем, кто не знаком с UNIX/Linux, сообщу, что cat — это команда, выводящая файл. Программу toupper я написал для преобразования текста в верхний регистр, a sort — программа, сортирующая строки текста. Все они прекрасно стыкуются. Теперь напишем более сложную утилиту. Это будет программа, определяющая, какой компьютер в вашей локальной сети наиболее вероятно заражен червем. Программа будет представлять собой один длинный канал. Звучит неожиданно? Все, что будет делать наша программа, — это искать подозрительные на заражение компьютеры. Иными словами, она выведет список хостов, нуждающихся в более внимательном осмотре. Тем не менее, ваши коллеги будут удивлены, уверяю вас. Программа не заменит вам хорошее антивирусное обеспечение, но я выбрал этот пример как хорошую иллюстрацию некоторых рудиментарных приемов программирования оболочки. Кроме того, вы узнаете кое-что новое о работе сетей. Когда мы закончим, в ваших руках будет простой инструмент, которым вы сможете пользоваться для диагностики этой конкретной проблемы в своей сети. С помощью этой программы мне удалось убедить руководство в необходимости купить настоящее антивирусное программное обеспечение. Каков признак того, что компьютер инфицирован червем? Надо проверить, какие компьютеры чаще других отправляют ARP-пакеты. Черви/вирусы/шпионские программы нередко пытаются соединиться со случайно выбранным компьютером локальной сети. Когда компьютер впервые пытается связаться с локальным IP-адресом, он отправляет ARP-пакет для выяснения Ethernet (МАС) — адреса. Нормальные (не-инфицированные) компьютеры обычно общаются лишь с несколькими компьютерами: с серверами, которые им нужны, и с их локальным маршрутизатором. Если обнаружится, что какой-то компьютер отправляет значительно больше ARP-пакетов, чем остальные, скорее всего, это можно считать признаком его заражения. Построим простой канал в оболочке, который будет собирать следующие 100 ARP-пакетов в сети и определять, какой хост сгенерировал больше пакетов, чем другие хосты того же уровня. Что-то вроде конкурса «Кто пошлет больше пакетов». В прошлую такую проверку я обнаружил, что червями заражены два из пятидесяти компьютеров сети. Команды, приведенные ниже, должны работать в любой системе UNIX/Linux или другой UNIX-подобной системе. Вам понадобится команда tcpdump и доступ с правами root. Команда which tcpdump сообщит вам, установлена ли команда tcpdump в вашей системе. Проверка пакетов в сети имеет этические аспекты. Выполняйте ее, только если у вас есть разрешение. Вот команда, получившаяся у меня в итоге (прошу прощения за испорченный сюрприз): $ sudo tcpdump — l -n агр | grep 'агр who-has' | \ head -100 | awk '{ print $NF }' |sort | uniq — с | sort — n Она такая длинная, что не помещается в одной строке этой книги, поэтому я разбил ее на две строки, а символом переноса служит обратный слэш. Вам не нужно набирать обратный слэш при вводе команды.[7] Не следует и нажимать клавишу Enter в этом месте. Вывод команды выглядит так: tcpdump: verbose output suppressed, use — v or — vv for full protocol decode listening on en0, link-type EN10MB (Ethernet), capture size 96 bytes 1 192.168.1.104 2 192.168.1.231 5 192.168.1.251 7 192.168.1.11 7 192.168.1.148 7 192.168.1.230 8 192.168.1.254 11 192.168.1.56 21 192.168.1.91 30 192.168.1.111 101 packets captured 3079 packets received by filter 0 packets dropped by kernel Не обращайте внимание на две первые и три последние строки. В остальных строках указано количество пакетов и IP-адрес. Этот эксперимент показал, что хост 192.168.1.111 отправил 30 ARP-пакетов, а хост 192.168.104 — только один пакет. Большинство машин редко отправляли пакеты за исследуемый период, но два хоста отправили в 4–6 раз больше пакетов, чем остальные. Это свидетельствовало о проблеме. Быстрое сканирование антивирусной программой — и оба хоста стали как новенькие. А теперь расскажу, как я строил эту командную строку. Я начал с команды: $ sudo tcpdump — l -n arp Здесь sudo означает, что следующая команда должна быть выполнена с правами пользователя root. Весьма вероятно, что она запросит пароль. Если в вашей среде нет sudo, вы можете воспользоваться аналогичной командой или выполнить эту последовательность от имени пользователя root.[8] Будьте внимательны. Человеку свойственно ошибаться, но настоящий храбрец не боится работать от имени root. Команда tcpdump прослушивает Ethernet. Флаг -1 нужен, если мы собираемся направить вывод другой программе. Дело в том, что, в отличие от других команд, tcpdump выполняет буферизацию выходных данных для ускорения работы. Однако при направлении вывода в канал нам это не нужно. Флаг — n отключает поиск в DNS для каждого найденного IP-адреса. Параметр arр означает, что команда tcpdump должна отслеживать только ARP-пакеты. (Если вас беспокоит этическая сторона вопроса, то должен сообщить вам хорошую новость. Если вы отфильтруете все, кроме ARP-пакетов, то на выходе будет очень мало частной информации.) Выполните эту команду на своем компьютере. Вообще, если вы будете проверять на практике все, о чем здесь прочитаете, вы многому научитесь. Эта команда не удаляет никакие данные. Но должен вас предупредить, что отслеживание пакетов может быть незаконным. Делайте это, только если у вас есть соответствующее разрешение. Когда я запускаю эту команду, вывод выглядит так: $ sudo tcpdump — n -l агр tcpdump: verbose output suppressed, use — v or — vv for full protocol decode listening on en0, link-type EN10MB (Ethernet), capture size 96 bytes 19:10:48,212755 arp who-has 192.168.1.110 (85:70:48:a0:00:10) tell 192.168.1.10 19:10:48,743185 arp who-has 192.168.1.96 tell 192.168.1.92 19:10:48,743189 arp reply 192.168.1.2 is-at 00:0e:e7:7a:b2:24 19:10:48. 743198 arp who-has 192.168.1.96 tell 192.168.1.111 ^C Чтобы прекратить вывод, я нажимаю клавиши CtrL–C Иначе он будет продолжаться вечно. Если вы получили сообщение об ошибке доступа, скорее всего, вы запустили команду не как суперпользователь. Команда tcpdump может быть выполнена только пользователем root. Вы ведь не хотите, чтобы вашу сеть прослушивал кто попало, правда? После заголовка идут строки вида «arp who-has X tell Y». Здесь Y — это хост, который задал вопрос. Вопрос имел примерно такое содержание: «Уважаемый хост с IP-адресом Х, не сообщите ли вы свой Ethernet (МАС) — адрес?» Вопрос отправляется широковещательным пакетом, поэтому мы видим все ARP-запросы в нашей локальной сети. Однако мы видим не так уж много ответов, поскольку они отправляются в виде однонаправленных пакетов, а мы находимся на концентраторе. В данном случае виден только один ответ, потому что мы находимся на одном концентраторе с тем компьютером (а, может, это компьютер, выполняющий команду, — этого я вам не скажу). Тем не менее, все хорошо; ведь нам нужны только те, кто задает вопросы. Итак, у вас есть источник информации. Преобразуем ее так, чтобы ею можно было воспользоваться. Во-первых, изолируем те строки вывода, которые нас интересуют. В данном случае это строки, содержащие «arp who-has»: $ sudo tcpdump — l -n arp | egrep 'arp who-has' Мы можем запустить эту команду и убедиться, что она ведет себя, как ожидалось. Единственная проблема в том, что команда работает безостановочно, пока мы не нажмем CtrL–C. Мы хотим получить достаточное количество строк и затем обработать их. Ограничимся первой сотней строк: $ sudo tcpdump — l -n arp | grep 'arp who-has' | head -100 Снова запустим команду и убедимся, что все хорошо. Во время тестирования этой команды у меня не хватило терпения, и я изменил 100 на 10. Это дало мне уверенность, что команда работает правильно, и в окончательном варианте я поставил 100. Вы, конечно, заметите в выводе кучу заголовков. Они направляются в поток stderr (прямо на экран) и не передаются в команду gгер. Итак, у нас есть сто строк с интересующими нас данными. Настало время статистических подсчетов. Какие хосты генерируют больше всего ARP-пакетов? Нам нужно выделить IP-адреса всех хостов, сгенерировавших ARP-пакет, и как-то подсчитать их количество. Начнем с выделения IP-адресов. Это шестое поле каждой строки, и мы можем воспользоваться следующей командой: awk '{ print $6 }' Этот маленький фрагмент кода awk является прекрасной идиомой для выделения конкретного поля из каждой строки текста. Должен сознаться, что мне было лень подсчитывать, в каком поле находятся данные, которые я хотел выделить. Было похоже, что это пятое поле, и я сначала пробовал указать $5. Не сработало, тогда я указал $6. Конечно! Мне следовало помнить, что в awk поля нумеруются с единицы, а не с нуля. Преимущество тестирования командной строки на каждом шаге в том и заключается, что мы достаточно рано обнаруживаем такие мелкие ошибки. Представьте, что было бы, если бы я написал всю командную строку сразу, а затем стал бы искать эту ошибку! Я ленив и нетерпелив. Мне не хотелось каждый раз ждать, пока будут собраны все сто ARP-пакетов. Поэтому я сохранил их один раз и затем использовал эти результаты. Я сохранил результаты во временном файле: $ sudo tcpdump — l -n arp | grep 'arp wno-has' | head -100 >/tmp/x Затем я применил свой код awk к этому временному файлу: $ cat /tip/x | awk '{ print $5 }' tell tell tell tell Оказывается, мне нужно не пятое поле. Попробуем шестое: $ cat /tmp/х | awk '{ print $6 }' 192.168.1.110 192.168.1.10 192.168.1.92 … Да, так лучше. Как бы то ни было, впоследствии я понял, что можно ублажать свою лень другим способом. Конструкция $NF обозначает последнее поле и позволяет мне вообще ничего не подсчитывать: $ cat /tmp/x | awk '{ print $HF }' 192.168.1.110 192.168.1.10 192.168.1.92 А почему не $LF? Ну, это было бы слишком просто. А если серьезно, NF означает «number of fields» (количество полей). То есть $NF обозначает NF-e поле слева. Но все это неважно. Просто запомните, что, если вам нужно последнее поле в строке, вы можете добавить $NF в awk: $ sudo tcpdump — l -n arp | egrep 'arp who-has' \ | head -100 | awk '{ print $NF }' Итак, на выходе мы получаем список IP-адресов. Проверьте это. (Именно так! Проверьте. Я подожду.) Теперь мы хотим подсчитать, сколько раз каждый IP-адрес появляется в нашем списке. Есть одна идиома, которую я всегда применяю именно для этой цели: sort | uniq — с Она сортирует данные, а затем выполняет команду uniq, которая исключает повторения из отсортированного списка. (То есть технически она устраняет повторения соседних строк, а сортировка списка гарантирует, что одинаковые строки будут соседствовать.) Флаг — с включает подсчет повторений и вставляет это число в начало каждой строки. Результат выглядит так: … 11 192.168.1.111 7 192.168.1.230 30 192.168.1.254 8 192.168.1.56 21 192.168.1.91 … Мы почти у цели! Мы знаем, сколько ARP-пакетов отправил каждый хост. Последнее, что мы должны сделать, — это отсортировать список, чтобы выявить самые «общительные» хосты. Для этого добавляем в конец канала конструкцию | sort — n, которая выполнит сортировку по номеру: $ sudo tcpdump — l -n arp | egrep 'arp who-has' | head -100 \ | awk '{ print $NF }' | sort | uniq — с | sort — n Выполнив эту команду, мы увидим отсортированный список. Если сеть не очень загружена, выполнение команды займет какое-то время. В локальной сети из 50 компьютеров, когда было мало пользователей, мне понадобилось около часа. Но это было уже после обнаружения компьютеров со шпионскими программами и их очистки. Перед этим на сбор ста ARP-пакетов я потратил всего несколько минут. В вашей домашней сети с одним или двумя компьютерами на выполнение команды может уйти несколько дней. Хосты кэшируют информацию, собранную ими с помощью ARP-запросов. Поэтому, поработав некоторое время, компьютер крайне редко отправляет ARP-пакеты,[9] если единственный компьютер, с которым он общается (в локальной сети), — это ваш маршрутизатор. Зато в сети из ста хостов подозреваемые обнаруживаются достаточно быстро. Теперь в вашем распоряжении имеется простой инструмент обнаружения атаки червей. Он не заменит тысячедолларовую систему распознавания атак и хорошую антивирусную программу, но, безусловно, поможет вам локализовать проблему, если она возникнет. Главное — он бесплатный, а вы узнали кое-что новое о программировании оболочки. Если вам захотелось отточить свое мастерство программиста, вот несколько небольших проектов: • Команда tcpdump выводит некоторую информацию в поток stderr. Есть ли способ предотвратить вывод этих сообщений? Если нет, то как получить менее «засоренный» вывод? • Преобразуйте описанную команду в сценарий. Поместите его в свой каталог bin, чтобы воспользоваться им в будущем. • Расширьте этот сценарий так, чтобы можно было определять, какой NIC сканировать, или добавьте другие возможности, которые сочтете нужными. • Можно запрограммировать команду tcpdump так, что она будет собирать только ARP-пакеты типа «who-has», и вы сможете обойтись без команды grep. Для этого изучите tcpdump поглубже. • Команда tcpdump может выполнять те же действия, что и head -100. Для этого изучите tcpdump поглубже. Получилось ли то же самое, что при head -100? Лучше или хуже стало? • awk — это полноценный язык программирования. Воспользуйтесь им, чтобы исключить аргументы grep и head. Как вы думаете, почему я предпочел выполнять три процесса, вместо того чтобы просто возложить все на awk? Microsoft Excel как альтернативный графический интерфейсРазработка графического интерфейса приложения требует 90 % всех усилий. Вот способ создания графического интерфейса для ленивых: храните данные в Microsoft Excel, но напишите макрос, который будет загружать эти данные на сервер для последующей обработки. Однажды я таким образом написал целое приложение. У нас был вебсайт, на котором были представлены различные события. Я устал обновлять веб-страницу вручную, но понимал, что для самостоятельной поддержки веб-сайта у секретарши не хватает технических навыков. Тогда я задумался над графическим интерфейсом, позволяющим вносить обновления даже неподготовленному пользователю. У меня были громадные планы: большая база данных MySQL и движок на РНР, который позволил бы пользователям входить в систему, обновлять информацию, пополнять список событий и т. д. Система должна была автоматически генерировать веб-страницы. Все было прекрасно на бумаге, и я не сомневаюсь, что если бы в моем распоряжении было сто лет на написание кода, результат был бы замечательным. Потом я понял, что на самом деле все изменения будет вносить только один человек. Тогда я создал для секретарши электронную таблицу Excel со всей необходимой информацией и написал макрос, который сохранял эту таблицу дважды: один раз на сервере в виде текстового файла с символом табуляции в качестве разделителя, а второй раз — в виде XLS-файла. Процесс на сервере должен был анализировать файл с табуляцией и генерировать веб-страницу автоматически. Пример таблицы показан на рис. 13.2. Создание кнопки выполняется в несколько шагов. Во-первых, для запоминания нужных действий используйте функцию записи макроса: 1. Запишите макрос: последовательно выберите команды меню Tools (Сервис) — > Macro (Макрос) — > Record New Macro (Начать запись). 2. Назовите макрос Save (Сохранить). 3. Сохраните таблицу как файл с символом табуляции в качестве разделителя на сетевом файловом сервере. 4. Сохраните файл в формате MS Excel Wolrkbook (Книга Mcrosoft Excel) (.xls) в своем каталоге. Важно, чтобы последняя операция сохранения файла использовала самый мощный формат MS Excel Wolrkbook (Книга Mcrosoft Excel), потому что таким образом будет установлен формат сохранения по умолчанию. Если затем кто-то сохранит файл с помощью команды File (Файл) — > Save (Сохранить), то будет использован именно этот формат.
Рис. 13.2. Электронная таблица со списком событий 5. Щелкните по кнопке Stop (Остановить запись) на панели инструментов, появляющейся на экране в режиме записи макроса. Теперь создайте кнопку и закрепите за ней макрос: 1. Выведите панель инструментов Forms (Формы): выберите команду View (Вид) — > Toolbars (Панель инструментов) — > Forms (Формы). 2. Щелкните по элементу Button (Кнопка) (выглядит как обычный прямоугольник). 3. Нарисуйте кнопку в том месте, где она должна находиться в таблице. 4. В ответ на вопрос выберите макрос, который только что создали. 5. Если вам впоследствии понадобится отредактировать кнопку, щелкните по ней при нажатой клавише Ctrl. Протестируйте макрос, щелкнув по кнопке. Отлично! Все работает! Проверьте дату и время сохранения файлов, чтобы убедиться, что таблица была сохранена дважды. (Возможно, Excel дважды спросит вас, нужно ли замещать существующий файл. Ответьте «Да».) Если вы хотите немного подправить макрос, это просто. Первое, что я сделал, — отредактировал макрос как раз в том месте, где выполняется сохранение файла: 1. Выберите команду Tools (Сервис) — > Macro (Макрос) — > Macros (Макросы). 2. Выберите макрос в списке открывшегося окна и щелкните по кнопке Edit (Изменить). Откроется редактор Visual Basic. 3. Закончив редактирование, сохраните файл и закройте редактор Visual Basic. ♥ В макросах Microsoft для переноса длинных строк используется символ подчеркивания (_). Окончательный макрос выглядит так: Sub Save() ' Macro recorded 5/22/2005 су Thomas Limoncelli ActiveWorkbook.SaveAs Filename:= _ "Y: \calendar\EventList.txt", FileFormat:= _ xlText, CreateBackup:= False ActiveWorkbook.SaveAs Filenames _ "Y: \calerdar\EventList.xls", FileFormat:= _ xlNormal, Password:= "", WritefiesPassword:= "", _ ReadOnlyRecommended:= False , CreateBackup:= False End Sub Теперь, когда у меня есть файл с символами табуляции в качестве разделителей, хранящийся на файловом сервере, мне нетрудно написать сценарий, который откроет этот файл, извлечет из него полезную информацию и на основании этой информации сгенерирует веб-страницу. С тех пор я часто пользуюсь этим приемом в ситуациях, когда мне не хочется писать пользовательский интерфейс, а пользователь умеет работать с MS Excel. Предоставление другим пользователям прав суперпользователяМеня нередко просят предоставить обычным пользователям право выполнять привилегированные операции, разрешенные только администратору. Это может быть опасно, и здесь требуется большая осторожность. В UNIX/Linux есть утилита sudo, позволяющая системному администратору предоставить пользователю возможность выполнить какую-нибудь команду под видом другого пользователя. Это очень строгая утилита, и она требует, чтобы системный администратор четко указал, какой пользователь (пользователи) какую команду (команды) будет выполнять от имени какого пользователя. Например, вы можете сконфигурировать утилиту так, что конкретный пользователь сможет выполнить некоторую команду от имени root. He сомневайтесь, что sudo позволит только этому человеку выполнять от имени root только эту команду, но важно, чтобы эта утилита проверяла параметры и не запрещала привилегированным пользователям выполнять разрешенные им операции. ♠ Очень рискованно создавать систему, в которой «обычным» пользователям разрешено выполнять «привилегированные» операции. В истории компьютерной безопасности полно случаев, когда добросовестные программисты случайно создавали в системе безопасности «дыры», позволяющие любому пользователя выполнять любую команду от имени пользователя root или administrator. Если вы испытываете сомнения, прочитайте книгу по безопасности или поищите ответы в FAQ. Предположим, что UNIX-команду mount для обращения к CD-ROM можно выполнять только пользователю root. Недопустимо конфигурировать sudo так, чтобы рядовой пользователь мог выполнить команду mount с любыми параметрами от имени root. Так он сможет вызвать сбой в работе системы или нарушить ее безопасность. Гораздо лучше, если вы разрешите пользователю выполнять от имени root некую новую команду (скажем, mountсd). Эта команда убедится, что пользователь указал именно те дисководы, к которым ему разрешено обращаться (с учетом умолчаний), и выполнит необходимые действия. Вероятно, вы предоставите этому пользователю и команду unmountсd. Автоматизируя операции, выполняемые другими пользователями, я предпочитаю строить три уровня: • Уровень 1. Программа, выполняющая основную задачу. • Уровень 2. Программа, которую пользователь запустит при помощи sudo. Она примет входные данные, проверит их, убедится, что он не пытается выполнить подозрительные действия, и вызовет первую программу. • Уровень 3. Дружественный пользователю интерфейс доступа к предыдущим слоям, например веб-интерфейс или программа с меню. Приведу пример. В одной фирме, где я работал, имелась процедура публикации новой версии веб-сайта фирмы в Интернете. В процедуре были задействованы три веб-сервера (на самом деле это были виртуальные серверы на двух компьютерах, но эти подробности несущественны). www-draft.example.com Здесь разрабатывалась новая версия нашего веб-сайта. www-qa.example.com Сюда копировался новый вариант сайта для тестирования качества. Сразу после создания копии для этих файлов устанавливался режим «только чтение». Если отдел контроля качества принимал сайт, мы должны были иметь гарантию, что опубликованным в Интернете окажется именно представленный вариант. www.example.com Это был собственно сайт, который видела публика. Веб-дизайнеры просили системных администраторов скопировать новую версию на www-qa.example.com. Отдел контроля качества, одобрив сайт, сообщал системным администраторам, что его можно опубликовать. Выполнение каждой из этих двух операций было автоматизировано командами: readyforqa Копировала эскиз сайта на сайт отдела контроля качества. golive Копировала сайт отдела контроля качества на сайт в Интернете. Отделу маркетинга требовался способ внесения экстренных изменений, когда сотрудники отдела контроля качества были вне досягаемости. Мы создали еще одну команду: emergency-draft-to-live Она копировала эскиз сайта на сайт в Интернете после того, как несколько раз переспрашивала «Are you sure?» (Вы уверены?). Эти три сценария образовали Уровень 2, который я упомянул выше. Уровнем 1 был сценарий, который фактически копировал данные с одного сайта на другой, попутно создавая резервную копию и устанавливая запрет на запись в файлы (а также меняя владельцев файлов). Уровень 1 был доступен только из учетной записи root, потому что он менял владельцев файлов и обращался к серверам по защищенным каналам. Команда sudo была запрограммирована так, как показано в табл. 13.1. Таблица 13.1. Таблица разрешений на обновление веб-сайта
Мы приложили определенные усилия, чтобы заставить руководство подписаться под этой схемой, т. е. поставить свои реальные подписи для гарантии того, что они понимают схему, с которой согласны на словах. Процесс получения подписей, как правило, шел очень туго. Он длился неделями. Представление информации в виде схемы облегчило руководству принятие решений. Менеджеры могли изучать ее и вносить изменения, сколько захотят. Преобразование окончательного варианта в файл конфигурации sudo было делом техники. В отношении Уровня 3 мы приняли решение о необходимости предоставить пользователям удобный способ обращения к этим командам. В качестве варианта мы рассматривали веб-интерфейс, но в данном случае пользователи удовлетворились программой, которая выводила меню с перечнем опций и запускала нужную команду. Меню работало без всякий привилегий (т. е. не под sudo), но вызывало программы Уровня 2 с помощью sudo, если это требовалось. Резюме• Автоматизация — великая вещь. Она экономит ваше время. Кроме того, она позволяет вам поручить работу другому менее квалифицированному сотруднику. • Есть четыре типа задач, с которыми сталкиваются системные администраторы: ― Простые задачи, выполняемые однократно ― Сложные задачи, выполняемые однократно ― Простые задачи, выполняемые часто ― Сложные задачи, выполняемые часто • Сложные однократные задачи и простые задачи, выполняемые часто, являются самыми подходящими кандидатами на автоматизацию. Несмотря на возможный соблазн автоматизировать сложные задачи, выполняемые часто, для их выполнения лучше использовать готовые программные пакеты (коммерческие или бесплатные). • Чтобы автоматизировать процесс, сначала убедитесь, что вы в состоянии выполнить его вручную. Затем задокументируйте все шаги и автоматизируйте каждый шаг в отдельности. После этого соберите шаги воедино. • Используя псевдонимы, вы облегчите себе ввод команд. Это справедливо и в отношении систем с командной строкой, и для приложений, например SSH. Установите псевдоним по возможности максимально близко к приложению. Например, если задать псевдоним в файле конфигурации SSH, то все системы, работающие с SSH, будут использовать этот псевдоним. • Команда make систем UNIX/Linux — исключительно мощный инструмент. Она предназначена не только для программистов. Вы можете применять ее для автоматизации задач системного администрирования. В системах UNIX/Linux, особенно на серверах, создавайте файл Makefile в каталоге /etc для автоматизации повседневных задач, таких как индексация псевдонимов, копирование данных и т. д. • Языки оболочек bash и /bin/sh гораздо сложнее и мощнее, чем вы думаете. Примеры, приведенные в этой главе, демонстрируют, как следует обрабатывать опции командной строки и даже как написать небольшой детектор вредоносных программ! • Если вы пишете длинную командную строку, тестируйте ее по частям. • Если вы пишете код для пользователей, возрастает важность интерфейса. Существуют технические приемы, позволяющие создавать хорошие пользовательские интерфейсы. Вы можете избавить себя от хлопот, переложив ввод данных на программу вроде MS Excel. Вы также можете создать программу с меню или веб-интерфейс, чтобы позволить обычным пользователям получать доступ к привилегированным системам. • Создавая код, позволяющий пользователям выполнять привилегированные операции, будьте предельно внимательны. В качестве базы используйте имеющиеся хорошо зарекомендовавшие себя средства безопасности, такие как sudo. С помощью таблицы разрешений объясните руководству, какой пользователь какие привилегии будет иметь. Разрешать или запрещать — дело руководства, а ваша задача заключается в том, чтобы помочь ему разобраться в вопросе. Прежде чем ввести систему в эксплуатацию, заручитесь согласием руководства. • Развиваясь как системный администратор, вы будете автоматизировать все больше и больше задач. Я советую вам изучить язык программирования, подходящий для целей системного администрирования, например Perl, Python, Ruby или Shell. Также обращайте внимание на технику работы в конкретных операционных системах. Эти вопросы освещаются в книгах серии «Cookbook» (Сборник рецептов) издательства O'Reilly, упомянутых ранее в этой книге. Примечания:4 Д. Бланк-Эдельман «Perl для системного администрирования», Символ-Плюс, 2001. 5 Эви Немет, Гарт Снайдер и др. «UNIX руководство системного администратора», BHV — Киев, 1998. 6 Традиционная особенность синтаксиса команды make состоит в том, что имена файлов, следующие за двоеточием, и отступы командных строк должны отделяться одним или несколькими символами табуляции, но ни в коем случае не пробелами; на распечатке они неразличимы, на это многие «попадались»; см. далее у автора. — Примеч. науч. ред. 7 Если используемая вами терминальная программа допускает ввод строки такой длины (что обычно выполняется). Но если эту команду предполагается, в свою очередь, использовать в тексте скрипта, то при переносе необходимо набирать обратный слэш. — Примеч. науч. ред. 8 Во многих UNIX-подобных системах в этом может помочь команда su. — Примеч. науч. ред. 9 Хосты кэшируют ARP-информацию, но на весьма непродолжительное время — порядка нескольких минут — в зависимости от используемой ОС, т. е. отправка ARP-запросов будет редкой, но не столь уж крайне редкой. — Примеч. науч. ред. |
|
|||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
||||||||||||||||||
|
|
||||||||||||||||||