|
||||
Разное
В предыдущей главе были представлены основы модели программирования СОМ и архитектуры удаленного доступа. Различные интерфейсы и методики СОМ рассматриваются на протяжении всей книги. Однако осталось несколько вопросов, не связанных ни с какой определенной главой, о которых следует рассказать подробно. Вместо того чтобы просто втиснуть эти вопросы в другие главы, которые были скомпонованы рационально или даже превышали разумные размеры, я отвел данную главу под хранилище для «маленьких» тем, которые не всегда подходят к другим частям книги. За исключением вводных разделов об указателях, управлении памятью и массивах, ни одна из этих тем не является жизненно необходимой для создания эффективных распределенных систем с СОМ. Помните об этом и расслабьтесь, в то время как ваши глаза будут скользить вдоль строк этой главы. Основы указателейСОМ, подобно DCE (Distributed Computing Environment – среда распределенных вычислений), ведет свое начало от языка программирования С. Хотя лишь немногие разработчики используют С для создания или использования компонентов СОМ, именно от С СОМ унаследовала синтаксис для своего языка определений интерфейсов (Interface Definition Language – IDL). Одной из наиболее сложных проблем при разработке и использовании интерфейсов является управление указателями. Рассмотрим такое простое определение метода IDL: HRESULT f([in] const short *ps); Если бы вызывающая программа должна была запустить этот метод так: short s = 10; HRESULT hr = p->f(&s); то величину 10 следовало бы послать объекту. Если бы этому методу нужно было выйти за границы апартамента, то интерфейсный заместитель был бы обязан разыменовать указатель и передать величину 10 в сообщение ORPC-запроса. Следующий клиентский код, хотя и написан целиком в традициях С, представляет собой более интересный случай: HRESULT hr = p->f(0); // pass a null pointer // передаем нулевой указатель Если вызывающий поток выполняется в апартаменте объекта, то заместителя нет и нулевой указатель будет передан прямо объекту. Но что если объект расположен в другом апартаменте и заместитель используется? Что в точности должен передать интерфейсный заместитель, чтобы показать, что был послан нулевой указатель? Кроме того, означает ли это, что интерфейсные заместители и заглушки должны проверять каждый указатель, не является ли он нулевым? Оказывается, бывают ситуации, в которых указатель никогда не должен быть нулевым, и другие ситуации, когда нулевые указатели, наоборот, чрезвычайно полезны как начальные значения. В последнем случае факт передачи нулевого указателя интерфейсному заместителю должен быть продублирован интерфейсной заглушкой в апартаменте объекта. Для того чтобы удовлетворить этим столь различным требованиям, СОМ позволяет разработчикам интерфейсов указывать точную семантику каждого параметра указателя. Чтобы показать, что указатель никогда не должен принимать нулевого значения, разработчик интерфейса может применить атрибут [ref]: HRESULT g([in, ref] short *ps); // ps cannot be a null ptr. // ps не может быть нулевым указателем Указатели, использующие атрибут [ref], называются ссылочными указателями (reference pointers). При IDL-определении, приведенном выше, следующий код со стороны клиента: HRESULT hr = p->g(0); // danger: passing null [ref] ptr. // опасность: передается нулевой указатель с атрибутом [ref] является ошибочным. И если p указывает на интерфейсный заместитель, то данный интерфейсный заместитель обнаружит нулевой указатель и возвратит вызывающей программе ошибку маршалинга, даже не передав метод текущему объекту. А чтобы сделать нулевой указатель допустимым значением параметра, в IDL-определении следует использовать атрибут [unique]: HRESULT h([in, unique] short *ps); // ps can be a null ptr. // ps может быть нулевым указателем Указатели, использующие атрибут [unique], называются уникальными указателями (unique pointers). При IDL-определении, приведенном выше, следующий код со стороны клиента: HRESULT hr = p->h(0); // relax: passing null [unique] ptr. // расслабьтесь: передается нулевой указатель с атрибутом [unique] является допустимым. Это означает, что интерфейсный заместитель должен подробно исследовать указатель перед тем, как разыменовать его. И что более важно: это означает, что интерфейсному заместителю необходимо записывать в ответ на ORPC-запрос не только разыменованную величину. Кроме нее, он должен записать тег, указывающий, был или не был передан нулевой указатель. Это добавляет к размеру ORPC-сообщения четыре байта на каждый указатель. Для большинства приложений эти добавочные четыре байта и то процессорное время, которое необходимо для выявления нулевого указателя[1], пренебрежимо малы по сравнению с преимуществами использования нулевых указателей в качестве параметров. Вообще говоря, схемы [ref] и [unique] мало отличаются по эффективности. Однако до сих пор не обсуждалась еще одна проблема, связанная с указателями. Рассмотрим следующий фрагмент на IDL: HRESULT j([in] short *ps1, [in] short *ps2); Имея такое IDL-определение, рассмотрим теперь следующий фрагмент кода со стороны клиента: short x = 100; HRESULT hr = p->j(&x, &х); // note: same ptr. passed twice // заметим: тот же самый указатель передан дважды Естественный вопрос: что должен делать интерфейсный заместитель при наличии одинаковых указателей? Если интерфейсный заместитель не делает ничего, тогда значение 100 будет передано в ORPC-запросе дважды: один раз для *ps1 и один раз для *ps2. Это означает, что заместитель посылает одну и ту же информацию дважды, впустую занимая сеть и тем самым уменьшая ее пропускную способность. Конечно, число байтов, занятых величиной 100, невелико, но если бы ps1 и ps2 указывали на очень большие структуры данных, то повторная передача существенно повлияла бы на производительность. Другой побочный эффект от невыявления дублирующего указателя состоит в том, что интерфейсная заглушка будет демаршалировать эти значения в два различных места памяти. Если бы семантика метода изменилась из-за тождественности двух таких указателей: STDMETHODIMP MyClass::j(short *ps1, short *ps2) { if (ps1 == ps2) return this->OneKindOfBehavior(ps1); else return this->AnotherKindOfBehavior(ps1, ps2); } то интерфейсный маршалер нарушил бы семантический контракт (semantic contract) интерфейса, что нарушило бы прозрачность экспорта в СОМ. Наличие атрибутов указателя [ref] и [unique] означает, что память, на которую ссылается указатель, не является ссылкой для какого-либо другого указателя в вызове метода и что интерфейсный маршалер не должен осуществлять проверку на дублирование указателей. Для того чтобы показать, что указатель может ссылаться на память, на которую ссылается другой указатель, разработчику IDL следует использовать атрибут [ptr]: HRESULT k([in, ptr] short *ps1, [in, ptr] short *ps2); Указатели, использующие атрибут [ptr], называются полными указателями (full pointers), потому что они наиболее близки к полному соответствию с семантикой языка программирования С. Имея такое IDL-определение, следующий код со стороны клиента: short x = 100; HRESULT hr = p->k(&x, &x); // note: same ptr. passed twice // заметим: тот же самый указатель передан дважды передаст значение 100 ровно один раз, поскольку атрибут [ptr] при параметре ps1 сообщает интерфейсному маршалеру, что следует выполнить проверку на дублирование для всех остальных указателей с атрибутом [ptr]. Поскольку параметр ps2 также использует атрибут [ptr], интерфейсный маршалер определит значение дублирующего указателя[2], а разыменует и передает значение только одного из указателей. Интерфейсная заглушка отметит, что это значение должно быть передано с обоими параметрами, ps1 и ps2, вследствие чего метод получит один и тот же указатель в обоих параметрах. Хотя полные указатели могут решать различные проблемы и в определенных случаях полезны, они не являются предпочтительными указателями в семантике СОМ. Дело в том, что в большинстве случаев разработчик знает заранее, что дублирующие указатели передаваться не будут. Кроме того, поскольку полные указатели обеспечивают более короткие ORPC-сообщения в случае, если они являются дублирующими указателями, то расход ресурсов процессора на поиск дублирующих указателей может стать нетривиальным с ростом числа указателей на каждый метод. Если разработчик интерфейса уверен, что никакого дублирования не будет, то разумнее учесть это и использовать либо уникальные, либо ссылочные указатели. Указатели и памятьИнтерфейсы, показанные в данной главе до настоящего момента, были довольно просты и использовали только примитивные типы данных. При применении сложных типов данных одной из наиболее серьезных проблем является управление памятью для параметров метода. Рассмотрим следующий прототип функции IDL: HRESULT f([out] short *ps); При наличии такого прототипа нижеследующий код вполне допустим с точки зрения С: short s; HRESULT hr = p->f(&s); // s now contains whatever f wrote // s теперь содержит все, что написал f Должно быть очевидно, как организована память для такой простой функции. Однако часто начинающие (и не только начинающие) программисты по ошибке пишут код, подобный следующему: short *ps; // the function says it takes a short *, so ... // функция говорит, что она берет * типа short, следовательно ... HRESULT hr = p->f(ps); При рассмотрении следующей допустимой реализации функции: STDMETHODIMP MyClass::f(short *ps) { static short n = 0; *ps = n++; return S_OK; } очевидно, что выделение памяти для короткого целого числа и передача ссылки на память в качестве аргумента функции является обязанностью вызывающей программы. О только что приведенной реализации заметим, что для функции неважно, откуда взялась эта память (например, динамически выделена из «кучи», объявлена как переменная auto в стеке), до тех пор, пока текущий аргумент ссылается на допустимую область памяти. Для подкрепления этого положения СОМ требует, чтобы все параметры с атрибутами [out], являющиеся указателями, были ссылочными указателями. Ситуация становится менее очевидной, когда вместо простых целых типов используются типы, определенные пользователем. Рассмотрим следующее IDL-определение: typedef struct tagPoint { short x; short у; } Point; HRESULT g([out] Point *pPoint); Как и в предыдущем примере, правильной является такая схема: вызывающая программа выделяет память для значений и передает ссылку на память, выделенную вызывающей программой: Point pt; HRESULT hr = p->g(&pt); Если вызывающая программа передала неверный указатель: Point *ppt; // random unitialized pointer // случайный неинициализированный указатель HRESULT hr = p->g(ppt); // where should proxy copy x & у to? // куда заместитель должен копировать x и у ? то не найдется легальной памяти, куда метод (или интерфейсный заместитель) мог бы записать значения x и y. Чем более сложные типы определяются пользователем, тем интереснее становится сценарий. Рассмотрим следующий код IDL: [uuid(E02E5345-l473-11d1-8C85-0080C73925BA),object ] interface IDogManager : IUnknown { typedef struct tagHUMAN { long nHumanID; } HUMAN; typedef struct tagDOG { long nDogID; [unique] HUMAN *pOwner; } DOG; HRESULT GetFromPound([out] DOG *pDog); HRESULT TakeToGroomer([in] const DOG *pDog); HRESULT SendToVet([in, out] DOG *pDog); } Отличительная особенность этого интерфейса состоит в том, что теперь вызывающая программа должна передать указатель на такой участок памяти, который уже содержит указатель. Можно показать, что для приведенного выше определения метода следующий код является правильным: DOG fido; // argument is a DOG *, so caller needs a DOG // аргументом является DOG *, поэтому вызывающей программе нужен DOG HUMAN dummy; // the DOG refers to an owner, so alloc space? // DOG ссылается на владельца, поэтому выделяем память? fido.pOwner = &dummy; HRESULT hr = p->GetFromPound(&fido); // is this correct? // правильно ли это? В данном коде предполагается, что вызывающая программа ответственна за выделение памяти для DOG, который передается по ссылке. В этом смысле код правилен. Однако в этом коде также предполагается, что он отвечает за управление любой памятью более низкого уровня, на которую могут сослаться обновленные значения объекта DOG. Именно здесь данный код отступает от правил СОМ. СОМ разделяет указатели, участвующие в вызове метода, на две категории. Любые именованные параметры метода, являющиеся указателями, относятся к указателям высшего уровня (top-level). Любой подчиненный указатель, который получен путем разыменования указателя высшего уровня, является вложенным (embedded) указателем. В методе GetFromPound параметр pDog считается указателем высшего уровня. Подчиненный указатель pDog->pOwner рассматривается как вложенный указатель. Отметим, что определение структуры DOG использует атрибут [unique] для явной квалификации семантики указателя для элемента структуры pOwner. Если бы семантика указателя не была квалифицирована явно, разработчик интерфейса мог бы применить принятый по умолчанию во всех интерфейсах для всех вложенных указателей атрибут [pointer_default]: [ uuid(E02E5345-1473-11d1-8C85-0080C73925BA), object, pointer_default(ref) // default embedded ptrs to [ref] // по умолчанию вложенные указатели [ref] ] interface IUseStructs : IUnknown { typedef struct tagNODE { long val; [unique] struct tagNODE *pNode; // explicitly [unique] // явно [unique] } NODE; typedef struct tagFOO { long val; long *pVal; // implicitly [ref] // неявно [ref] } FOO; HRESULT Method([in] FOO *pFoo, [in, unique] NODE *pHead); } Атрибут [pointer_default] применяется только к тем вложенным указателям, семантика которых не квалифицирована явно. В приведенном выше определении интерфейса единственный указатель, к которому это относится, – это элемент данных pVal структуры FOO. Элемент pNode структуры NODE явно квалифицирован как уникальный указатель, поэтому установка [pointer_default] на него не влияет. На параметры метода pFoo и pHead атрибут [pointer_default] также не влияет, поскольку они являются указателями высшего уровня и по умолчанию [ref], если только они не квалифицированы явно иным образом (как в случае с pHead). Основная причина, по которой вложенные указатели имеют в СОМ отдельный статус, заключается в том, что они предъявляют особые требования к организации памяти. Для параметров с атрибутом [in] различие между указателями высшего уровня и вложенными указателями не слишком существенно, так как вызывающая программа обеспечивает метод всеми значениями и поэтому должна заранее выделить память, которую эти значения будут занимать: HUMAN bob = { 2231 }; DOG fido = { 12288, &bob }; // fido is owned by bob // fido принадлежит bob'y HRESULT hr = p->TakeToGroomer(&fido); // this is correct! // это правильно! В то же время разграничение между указателями высшего уровня и вложенными является существенным, когда оно касается организации памяти для параметров [out] и [in,out]. Для обоих параметров, [out] и [in,out], память, на которую ссылаются указатели высшего уровня, управляется вызывающим оператором, как и в случае параметров [in]. Для вложенных же указателей, которые появляются в параметрах [out] и [in, out], память управляется вызываемым оператором (самим методом). Причина появления этого правила заключается в том, что глубина вложения типов данных может быть сколь угодно большой. Например, в таком определении типа: typedef struct tagNODE { short value; [unique] struct tagNODE *pNext; } NODE: вызывающему оператору невозможно заранее определить, сколько подэлементов понадобится разместить. Однако, поскольку вызываемый оператор (данный метод) будет снабжать данными каждый узел, он благополучно может выделить память для каждого необходимого узла. При наличии правила, по которому разработчики метода должны выделять память при инициализации любых вложенных указателей, возникает естественный вопрос, откуда методы должны получить эту память, чтобы вызывающие операторы знали, как освободить ее после прочтения всех возвращенных значений? Ответом является распределитель памяти (task allocator) СОМ-задачи. Распределителем памяти задачи СОМ называется распределитель памяти, индивидуальный для каждого процесса, используемый исключительно для выделения памяти вложенным указателям с атрибутами [out] и [in,out]. Проще всего использовать этот распределитель памяти СОМ-задачи посредством применения трех API-функций СОМ: void *CoTaskMemAlloc(DWORD cb); // allocate cb bytes // размещаем cb байтов void CoTaskMemFree(void *pv); // deallocate memory at *pv // освобождаем память в *pv void *CoTaskMemRealloc(void *pv,DWORD cb); // grow/shrink *pv // расширяем/сжимаем *pv Семантика этих трех функций такая же, как у их эквивалентов из динамической библиотеки С: malloc, free и realloc. Разница состоит в том, что они предназначены исключительно для выделения памяти параметрам типа вложенных указателей с атрибутами [out] и [in,out]. Другое важное отличие состоит в том, что подпрограммы из динамической библиотеки С нельзя использовать для выделения памяти в одном модуле и освобождения ее в другом. Дело в том, что детали реализации каждой динамической библиотеки С являются специфическими и изменяются при смене компилятора. Так как все участники согласились использовать один и тот же распределитель, предлагаемый СОМ, нет проблемы с освобождением клиентом памяти, которая выделена объектом, скомпилированным в отдельной DLL. Чтобы понять, как используются на практике блоки памяти, выделенные вызываемым оператором, рассмотрим приводившийся ранее метод GetFromPound: HRESULT GetFromPound([out] DOG *pDog); В то время как память для объекта DOG должна быть выделена вызывающей программой (pDog является указателем высшего уровня), память для объекта HUMAN должна быть выделена реализацией метода с использованием распределителя памяти задачи (pDog->pOwner является вложенным в [out]-параметр указателем). Реализация метода выглядела бы примерно так: STDMETHODIMP GetFromPound(/*[out]*/DOG *pDog) { short did = LookupNewDogId(); short hid = LookupHumanId(did); pDog->nDogID = did; // allocate memory for embedded pointer // выделяем память для вложенного указателя pDog->pOwner = (HUMAN*) CoTaskMemAlloc(sizeof(HUMAN)); if (pDog->pOwner == 0) // not enough memory // недостаточно памяти return R_OUTOFMEMORY; pDog->pOwner->nHumanID = hid; return S_OK; } Отметим, что метод возвращает специальный HRESULT E_OUTOFMEMORY, указывающий на то, что операция прервана из-за нехватки памяти. Программа, вызывающая метод GetFromPound, ответственна за освобождение любой памяти, выделенной вызываемым методом, после использования соответствующих значений: DOG fido; HRESULT hr = p->GetFromPound(&fido); if (SUCCEEDED(hr)) { printf(«The dog %h is owned by %h», fido.nDogID, fido.pOwner->nHumanID); // data has been consumed, so free the memory // данные использованы, поэтому освобождаем память CoTaskMemFree(fido.pOwner); } В случае сбоя метода клиент может предположить, что не было выделено никакой памяти, если только в документации не указан другой исход. В только что приведенном примере использован чистый [out]-параметр. Управление [in, out]– параметрами несколько более сложно. Вложенные указатели для [in, out]-параметров должны быть размещены вызывающей программой с помощью распределителя памяти задачи. Если методу требуется повторно распределить память, переданную клиентом, то метод должен сделать это с использованием CoTaskMemRealloc. Если же вызывающая программа не имеет никакой информации для передачи методу, то она может передать ему на входе нулевой указатель, и тогда метод может использовать CoTaskMemRealloc (который без проблем принимает нулевой указатель и делает то, что нужно). Подобным же образом, если у метода нет информации для обратной передачи в вызывающую программу, он может просто освободить память, на которую ссылается вложенный указатель. Рассмотрим следующее определение метода IDL: HRESULT SendToVet([in, out] DOG *pDog); Пусть у вызывающей программы имеется легальное значение HUMAN, которое она хочет передать как параметр. Тогда клиентский код может выглядеть примерно так: HUMAN *pHuman = (HUMAN*)CoTaskMemAllocc(sizeof(HUMAN)); pHuman->nHumanID = 1522; DOG fido = { 4111, pHuman }; HRESULT hr = p->SendToVet(&fido); // [in, out] if (SUCCEEDED(hr)) { if (fido.pOwner) printf(«Dog is now owned by %h», fido.pOwner->nHumanID); CoTaskMemFree(fido.pOwner); // OK to free null ptr. // можно освободить нулевой указатель } Реализация метода могла бы повторно использовать буфер, используемый вызывающей программой, или выделить новый буфер в случае, если вызывающая программа передала нулевой вложенный указатель: STDMETHODIMP MyClass::SendToVet(/*[in, out]*/DOG *pDog) { if (fido.pOwner == 0) fido.pOwner = (HUMAN*)CoTaskMemAlloc(sizeof (HUMAN)); if (fido.pOwner == 0) // alloc failed // сбой выделения памяти return E_OUTOFMEMORY; fido.pOwner->nHumanID = 22; return S_OK; } Поскольку работа с [in,out]-параметрами в качестве вложенных указателей имеет ряд тонкостей, в документации на интерфейс часто повторяются правила управления памятью для вложенных указателей. Приведенные выше фрагменты кода используют наиболее удобный интерфейс для СОМ-распределителя памяти задач. До появления версии СОМ под Windows NT основная связь с распределителем памяти задачи осуществлялась через его интерфейс IMallос: [ uuid(00000002-0000-0000-C000-000000000046),local,object] interface IMalloc : IUnknown { void *Alloc([in] ULONG cb); void *Realloc ([in, unique] void *pv, [in] ULONG cb); void Free([in, unique] void *pv); ULONG GetSize([in, unique] void *pv); int DidAlloc([in, unique] void *pv); void HeapMinimize(void); } Для получения доступа к интерфейсу IMalloc распределителя памяти задачи в СОМ имеется API-функция CoGetMalloc: HRESULT CoGetMalloc( [in] DWORD dwMemCtx, // reserved, must be one // зарезервировано, должно равняться единице [out] IMalloc **ppMalloc); // put it here! // помещаем его здесь! Это означает, что вместо вызова удобного метода CoTaskMemAlloc: HUMAN *pHuman = (HUMAN*)CoTaskMemAlloc(sizeof(HUMAN)); можно использовать следующую менее удобную форму: IMalloc *pMalloc = 0; pHuman = 0; HRESULT hr = CoGetMalloc(1, &pMalloc); if (SUCCEEDED(hr)) { pHuman = (HUMAN*)pMalloc->Alloc(sizeof(HUMAN)); pMalloc->Release(); } Преимущество последней технологии заключается в том, что она совместима с ранними, до Windows NT, версиями СОМ. Но в целом предпочтительнее использовать CoTaskMemAlloc и другие, поскольку эти методы требуют меньше программного кода и поэтому меньше подвержены ошибкам программирования. До сих пор обсуждение распределителя памяти задачи было сфокусировано на вопросах, как и когда объекты выделяют память, а клиенты – освобождают ее. Однако не обсуждалось, что происходит, когда объект и клиент размещаются в различных адресных пространствах. Это во многом связано с отсутствием различия в способах реализации клиентов и объектов при использовании интерфейсных маршалеров. СОМ-распределитель памяти задачи получает свою память из закрытого адресного пространства процессов. С учетом этого сокрытие того обстоятельства, что распределитель памяти задачи не может охватить оба адресных пространства, является делом интерфейсной заглушки и интерфейсного заместителя. Когда интерфейсная заглушка вызывает метод объекта, она маршалирует любые [out]– или [in, out]-параметры в ответное ORPC-сообщение. Как показано на рис. 7.1, по завершении этого маршалинга интерфейсная заглушка (которая в конечном счете является внутриапартаментным клиентом данного объекта) освобождает с помощью метода CoTaskMemFree любую память, выделенную вызываемой программой. Это эффективно освобождает всю память, выделенную в течение вызова метода внутри адресного пространства объекта. При получении ответного ORPC-сообщения интерфейсный заместитель с помощью метода CoTaskMemAlloc выделяет пространство для всех параметров, размещаемых в вызываемой программе. 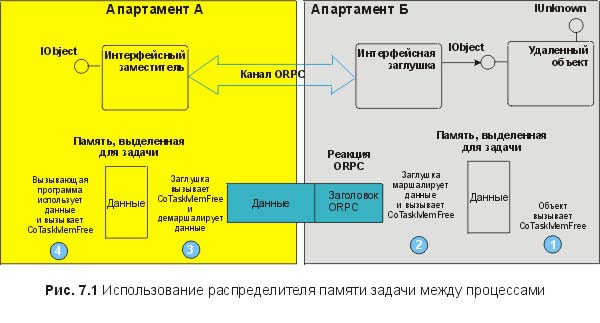 Когда эти блоки памяти освобождаются настоящим клиентом с помощью CoTaskMemFree, это эффективно освобождает всю память, выделенную в результате вызова метода, внутри адресного пространства клиента. Поскольку программисты печально известны своим пренебрежением к освобождению памяти, иногда бывает полезно следить за активностью распределителя памяти задачи в процессе (или отсутствием таковой активности). Для обеспечения этого контроля СОМ предлагает подключить к распределителю памяти задачи определяемый пользователем шпионский объект (spy object), который будет уведомляться до и после каждого вызова распределителя памяти. Этот шпионский объект, определяемый пользователем, должен реализовать интерфейс IMallocSpy: [ uuid(0000001d-0000-0000-C000-000000000046),local,object ] interface IMallocSpy : IUnknown { ULONG PreAlloc([in] ULONG cbRequest); void *PostAlloc([in] void *pActual); void *PreFree([in] void *pRequest,[in] BOOL fSpyed); void PostFree([in] BOOL fSpyed); ULONG PreRealloc([in] void *pRequest,[in] ULONG cbRequest, [out] void **ppNewRequest,[in] BOOL fSpyed); void *PostRealloc([in] void *pActual, [in] BOOL fSpyed); void *PreGetSize([in] void *pRequest, [in] BOOL fSpyed); ULONG PostGetSize([in] ULONG cbActual,[in] BOOL fSpyed); void *PreDidAlloc([in] void *pRequest, [in] BOOL fSpyed); int PostDidAlloc([in] void *pRequest, [in] BOOL fSpyed, [in] int fActual); void PreHeapMinimize(void); void PostHeapMinimize(void); } Отметим, что для каждого метода IMalloc интерфейс IMallocSpy имеет два метода: один, вызываемый СОМ до того, как действующий распределитель памяти задачи начнет свою работу, и второй, вызываемый СОМ после того, как распределитель памяти выполнил свою работу. В каждом «предметоде» (premethod) предусмотренный пользователем шпионский объект может изменять параметры, передаваемые пользователем распределителю памяти. В каждом «постметоде» (postmethod) шпионский объект может изменять результаты, возвращаемые действующим распределителем памяти задачи. Это дает возможность шпионскому объекту выделять дополнительную память, чтобы добавить к каждому блоку памяти отладочную информацию. В СОМ имеется API-функция для регистрации шпиона распределения памяти (Malloc spy) всего процесса: HRESULT CoRegisterMallocSpy([in] IMallocSpy *pms); В каждом процессе может быть зарегистрирован только один шпион распределения памяти (CoRegisterMallocSpy возвратит CO_E_OBJISREG в том случае, если уже зарегистрирован другой шпион). Для удаления шпиона распределения в СОМ предусмотрена API-функция CoRevokeMallocSpy: HRESULT CoRevokeMallocSpy(void); СОМ не позволит отменить полномочия шпиона распределения до тех пор, пока не освобождена память, выделенная действующим шпионом. МассивыПо умолчанию указатели, передаваемые через параметры, полагаются указателями на единичные экземпляры, а не на массивы. Для передачи массива в качестве параметра можно использовать синтаксис С для массивов и/или специальные атрибуты IDL для представления различной информации о размерности массива. Простейший способ передачи массивов – задать размерность во время компиляции: HRESULT Method1([in] short rgs[8]); Такое задание называется массивом постоянной длины (fixed array) и является наиболее простым для выражения на языке IDL и одновременно – наиболее простым и компактным представлением во время выполнения. Для такого массива интерфейсный заместитель выделит 16 байт (8 * sizeof (short)) в сообщении ORPC-запроса, а затем скопирует в сообщение все восемь элементов. Как только сервер получает ORPC-запрос, интерфейсная заглушка будет использовать память непосредственно из принимаемого блока в качестве аргумента функции, как показано на рис. 7.2.  Поскольку размер массива является постоянным и все содержимое массива уже содержится в принимаемом буфере, интерфейсная заглушка достаточно разумна, чтобы повторно использовать передаваемую память буфера в качестве текущего аргумента метода. Только что показанный метод полезен, если во всех случаях единственно разумной длиной массива является 8. Это позволяет вызывающей программе пересылать любой выбранный ею массив из коротких целых чисел (shorts), при условии, что этот массив состоит только из восьми элементов: void f(IFoo *pFoo) { short rgs[8] = { 1, 2, 3, 4, 5, 6, 7, 8 }; pFoo->Method1(rgs); } На практике предсказание подходящей длины массива невозможно, так как слишком малая длина означает, что будет передано недостаточно элементов, а слишком большая длина приведет к чрезмерному объему передаваемого сообщения. Более того, если массив состоит из сложных типов данных, то маршалинг элементов за пределами фактического размера массива может обойтись весьма дорого и/или привести к ошибкам маршалинга. Тем не менее, массивы постоянной длины полезны в тех случаях, когда размер массива не изменяется и известен во время формирования интерфейса. Чтобы можно было определять размеры массивов во время выполнения, IDL (и используемый сетевой протокол NDR) разрешает вызывающей программе задавать длину массива на этапе выполнения. Массивы такого типа называются совместимыми (conformant). Максимальный допустимый индекс совместимого массива можно задавать либо во время выполнения, либо во время компиляции, а длина, называемая соответствием (conformance) массива, передается раньше чем текущие элементы, как это показано на рис. 7.3. Как и в случае массива постоянной длины, совместимые массивы могут передаваться в реализацию метода непосредственно из передаваемого буфера без какого-либо дополнительного копирования, так как в передаваемом сообщении всегда присутствует все содержимое массива. Чтобы предоставить вызывающей программе возможность задать соответствие массива, IDL использует атрибут [size_is]: HRESULT Method2([in] long cElems, [in, size_is(cElems)] short rgs[*]); или HRESULT Method3([in] long cElems, [in, size_is (cElems)] short rgs[]); или HRESULT Method4([in] long cElems, [in, size_is(cElems)] short *rgs);  Все эти типы являются эквивалентными в терминах базового пакетного формата. Любой из этих методов дает вызывающей программе возможность определить соответствующий размер массива следующим образом: void f(IFoo *pFoo) { short rgs[] = { 1, 2, 3, 4, 5, 6, 7, 8 }; pFoo->Method2(8, rgs); } Выражение, используемое атрибутом [size_is] указанным выше способом, может содержать любые другие параметры того же метода, а также арифметические, логические и условные операторы. К примеру, следующий IDL-код является допустимым и достаточно простым для понимания: HRESULT Method5([in] long arg1, [in] long arg2, [in] long arg3, [in, size_is(arg1 ? (arg3+1) : (arg1 & arg2))] short *rgs); Вызовы функции или другие языковые конструкции, способные вызвать побочные эффекты (такие, как операторы ++ и –), запрещены в выражениях атрибута [size_is]. Если атрибут [size_is] используется для описания совместимого массива, вложенного внутрь какой-либо структуры, он может применять любые другие элементы этой структуры: typedef struct tagCOUNTED_SHORTS { long cElems; [size_is(cElems)] short rgs[]; } COUNTED_SHORTS; HRESULT Method6([in] COUNTED_SHORTS *pcs); из чего следует, что в вызывающей программе будет написан следующий код: void SendFiveShorts (IFoo *pFoo) { char buffer [sizeof (COUNTED_SHORTS) + 4 * sizeof (short)]; COUNTED_SHORTS& rcs = *reinterpret_cast<COUNTED_SHORTS*>(buffer); rcs.cElems = 5; rcs.rgs[0] = 0; rcs.rgs[1] = 1; rcs.rgs[2] = 2; rcs.rgs[3] = 3; rcs.rgs[4] = 4; pFoo->Method6(&rcs); } IDL также поддерживает атрибут [max_is], который является стилистической вариацией атрибута [size_is]. Атрибут [size_is] показывает число элементов, которое может содержать массив; атрибут [max_is] показывает максимальный допустимый индекс в массиве (который на единицу меньше числа элементов, содержащихся в массиве). Это означает, что два приведенных ниже описания эквивалентны друг другу: HRESULT Method7([in, size_is(10)] short *rgs); HRESULT Method8([in, max_is(9)] short *rgs); Интересно, что хотя в атрибутах [size_is] могут быть использованы константы, как это показано выше, немного более эффективным представляется использование массива постоянной длины. Если используется совместимый массив, то в предыдущих примерах размер соответствия должен быть передан, несмотря на то, что его величина статична и известна на этапе компиляции как интерфейсному заместителю, так и интерфейсной заглушке. Если бы содержимое массивов передавалось только от вызывающей программы в реализацию метода, то совместимый массив был бы достаточен почти для любых целей. Однако во многих случаях вызывающая программа хочет передать объекту пустой массив и получить его обратно заполненным нужными значениями. Как показано ниже, совместимые массивы можно использовать в качестве выходных параметров: HRESULT Method9([in] long cMax, [out, size_is(cMax)] short *rgs); из чего следует такое использование со стороны вызывающей программы: void f(IFoo *pFoo) { short rgs[100]; pFoo->Method9(100, rgs); } а также следующая реализация со стороны сервера: HRESULT CFoo::Method9(long cMax, short *rgs) { for (long n = 0; n < cMax; n++) rgs[n] = n * n; return S_OK; } Но что, если реализация метода не может правильно заполнить весь массив допустимыми элементами? В предыдущем фрагменте кода, даже если метод инициализирует только первые cMax/2 элементов массива, заглушка со стороны сервера, тем не менее, передаст весь массив из cMax элементов. Ясно, что это неэффективно, и для исправления этого положения в IDL и NDR имеется третий тип массивов, – переменный массив (varying array). Переменный массив – это массив, который имеет постоянную длину, но может содержать меньше допустимых элементов, чем позволяет его фактическая емкость. Вне зависимости от фактической длины массива будет передаваться единое непрерывное подмножество содержимого переменного массива. Для задания подмножества элементов, подлежащих передаче, IDL использует атрибут [length_is]. В отличие от атрибута [size_is], описывающего длину массива, атрибут [length_is] описывает фактическое содержимое массива. Рассмотрим следующий код на IDL: HRESULT Method10([in] long cActual, [in, length_is(cActual)] short rgs[1024]); Во время передачи первым будет передано значение cActual, которое называется переменной длиной (variance) массива, и лишь затем сами величины. Для того чтобы переданный блок (region) мог появиться в любом месте массива, а не только в его начале, IDL и NDR поддерживают также атрибут [first_is], который указывает место, где начинается передаваемый блок. Данная величина смещения будет также передаваться вместе с содержимым массива, чтобы демаршалер знал, какая часть массива инициализируется. Аналогично тому, как атрибут [size_is] имел свою стилистическую вариацию [max_is], [length_is] также имеет вариацию – [last_is], в которой используется индекс вместо счетчика. Два следующих определения эквивалентны: HRESULT Metnod11([in, first_is(2), length_is(5)] short rgs(8]); HRESULT Method12([in, first_is(2), last_is(6)] short rgs[8]); Оба метода инструктируют маршалер передавать только пять элементов массива, но демаршалирующая сторона выделяет место для восьми элементов и поступающие значения копируются в соответствующие места. Любые элементы, которых нет в передаваемом буфере, будут обнуляться. Переменные массивы могут уменьшить объем сетевых передач, так как передаются только необходимые элементы. Однако, как показано на рис. 7.4, переменные массивы менее эффективны, чем совместимые массивы, в смысле избыточного копирования памяти. Массив, передаваемый в реализацию метода заглушкой со стороны сервера, размещен в отдельном блоке динамически распределяемой памяти («в куче»). Вначале этот блок в процессе инициализации заполняется нулями, а затем содержимое передаваемого буфера копируется в соответствующие места памяти. Это приводит к одному или двум дополнительным проходам по памяти массива перед входом в метод, что для больших массивов может ухудшать производительность. Нельзя сказать, что переменные массивы бесполезны, но при использовании только в качестве входных параметров переменный массив значительно менее эффективен, чем логически эквивалентный ему совместимый массив. Подобно массивам постоянной длины, переменные массивы требуют от разработчика интерфейса задания соответствия/длины во время компиляции. Это обстоятельство значительно ограничивает использование переменных массивов, так как на практике затруднительно предсказать оптимальный размер буфера для всех вариантов использования интерфейса (например, у некоторых клиентов могут быть жесткие ограничения на использование памяти, а другие могут назначить более высокую плату за прием-передачу и поэтому предпочли бы большие буферы).  К счастью, и IDL, и NDR позволяют задавать как содержимое (переменную длину), так и длину (соответствие) для данного массива путем комбинирования атрибутов [size_is] и [length_is]. При использовании обоих этих атрибутов массив носит название совместимого переменного массива, или просто открытого (open) массива. Для задания открытого массива необходимо просто дать возможность вызывающей программе устанавливать и длину, и содержимое через параметры: HRESULT Method13([in] cMax, [in] cActual, [in, size_is(cMax), length_is(cActual)] short rgs[]); или HRESULT Method14([in] cMax, [in] cActual, [in, size_is(cMax), length_is(cActual)] short rgs[*]); или HRESULT Method15([in] cMax, [in] cActual, [in, size_is(cMax), length_is(cActual)] short *rgs); каждый из которых предполагает такое использование со стороны клиента: void f(IFoo *pFoo) { short rgs[8]; rgs[0] = 1; rgs[1] = 2; pFoo->Method13(8, 2, rgs); } Как показано на рис. 7.5, при передаче открытого массива маршалер сначала выяснит длину массива, а затем смещение и длину его фактического содержимого. Как и в случае переменного массива, длина массива может быть больше, чем количество передаваемых элементов. Это означает, что содержимое передаваемого буфера не может быть передано непосредственно вызывающей программе, поэтому используется второй блок памяти, что увеличивает расход памяти.  Совместимые массивы являются самым полезным типом массивов для входных параметров. Открытые массивы наиболее полезны для выходных или входных/выходных параметров, поскольку они позволяют вызывающей программе выделять буфер произвольного размера, несмотря на то, что передаваться будет только необходимое в каждом случае количество элементов. IDL для обеспечения использования этих типов выглядит следующим образом: HRESULT Method16([in] long cMax, [out] long *pcActual, [out, size_is(cMax), length_is(*pcActual)] short *rgs); из чего следует такое использование со стороны клиента: void f(IFoo *pFoo) { short rgs[8]; long cActual; pFoo->Method16(8, &cActual, rgs); // .. process first cActual elements of rgs // .. обрабатываем первые cActual элементов из массива rgs } в то время как реализация со стороны сервера выглядит примерно так: HRESULT CFoo::Method16(long cMax, long *pcActual, short *rgs) { *pcActual = min(cMax,5); // only write 1st 5 elems // записываем только первые пять элементов for (long n = 0; n < *pcActual; n++) rgs[n] = n * n; return S_OK; } Это позволяет вызывающей программе контролировать задание размеров буфера, а реализация метода контролирует фактическое количество переданных элементов. Если открытый массив будет использоваться в качестве входного/выходного параметра, то следует указать переменную длину массива в каждом направлении. Если число элементов на входе может отличаться от числа элементов на выходе, то параметр переменной длины тоже должен иметь входной/выходной тип: HRESULT Method17([in] long cMax, [in, out] long *pcActual, [in, out, size_is(cMax), length_is(*pcActual)] short *rgs); что предполагает следующий код на стороне клиента: void f(IFoo *pFoo) { short rgs[8]; rgs[0] = 0; rgs[1] = 1; long cActual = 2; pFoo->Method17(8, &cActual, rgs); // .. process first cActual elements of rgs // .. обрабатываем первые cActual элементов из массива rgs } Если число элементов на входе и на выходе одно и то же, то подойдет совместимый массив: HRESULT Method18([in] long cElems, [in, out, size_is(cElems)] short *rgs); Данный метод использует эффективность совместимого массива, и его гораздо проще использовать. Приведенные выше примеры оперировали с одномерными массивами. Рассмотрим следующий прототип на С: void g(short **arg1); Этот прототип может означать в С все, что угодно. Возможно, функция ожидает указатель на одно короткое целое число: void g(short **arg1) { // return ptr to static // возвращаем указатель на static static short s; *arg1 = &s; } Или, возможно, функция ожидает массив из 100 коротких указателей: void g(short **arg1) { // square 100 shorts by ref // квадрат из 100 коротких целых указателей for (int n = 0; n < 100; n++) *(arg1[n]) *= *(arg1[n]); } А также, возможно, функция ожидает указатель на указатель на массив коротких целых: void g(short **arg1) { // square 100 shorts // квадрат из 100 коротких целых for (int n = 0; n < 100; n++) (*arg1)[n] *= (*arg1)[n]; } Этот синтаксический кошмар разрешается в IDL использованием такого синтаксиса, который часто побуждает пользователей-новичков бежать за утешением к документации. Атрибуты IDL [size_is] и [lengtn_is] принимают переменное количество разделенных запятой аргументов, по одному на каждый уровень косвенности. Если параметр пропущен, то считается, что соответствующий уровень косвенности является указателем на экземпляр, а не на массив. Для того чтобы показать, что параметр является указателем на указатель на одиночный экземпляр, не требуется более никаких атрибутов: HRESULT Method19([in] short **pps); что означает такое расположение в памяти: pps -> *pps-> **pps Для того чтобы показать, что параметр является указателем на массив указателей на экземпляры, нужно написать следующий код IDL: HRESULT Method20([in, size_is(3)] short **rgps); что в памяти будет выглядеть примерно так: rgps -> rgps[0] -> *rgps[0] rgps[1] -> *rgps[1] rgps[2] -> *rgps[2] Для того чтобы показать, что параметр является указателем на указатель на массив экземпляров, следует написать такой код на IDL: HRESULT Method21([in, size_is(,4)] short **pprgs); что в памяти будет выглядеть следующим образом: pprgs -> pprgs -> (pprgs)[0] (pprgs)[1] (pprgs)[2] (pprgs)[3] Для того чтобы показать, что параметр является массивом указателей на массивы экземпляров, нужно написать следующее: HRESULT Method22([in, size_is(3,4)] short **rgrgs); что в памяти будет выглядеть примерно так: rgrgs -> rgrgs[0] -> rgrgs[0][0] rgrgs[0][1] rgrgs[0][2] rgrgs[0][3] rgrgs[1] -> rgrgs[1][0] rgrgs[1][1] rgrgs[1][2] rgrgs[1][3] rgrgs[2] -> rgrgs[2][0] rgrgs[2][1] rgrgs[2][2] rgrgs[2][3] Данный синтаксис, быть может, оставляет желать лучшего, тем не менее, он обладает большей гибкостью и меньшей неоднозначностью, чем на С. Важно отметить, что приведенный выше метод IDL задает многомерный массив; формально он представляет собой массив указателей на массив указателей на экземпляры. Это не то же самое, что многомерный массив в языке С, который может быть определен в IDL с использованием стандартного синтаксиса С: HRESULT Method23([in] short rgrgs[3][4]); Данный синтаксис предполагает, что все элементы массива будут размещены в памяти непрерывно, что определенно не совпадает с предположением предыдущего примера. Допускается задавать первое измерение многомерного массива с помощью атрибута [size_is]: HRESULT Method24([in, size_is(3)] short rgrgs[][4]); однако нельзя задавать никакого иного измерения, кроме крайнего левого. Выражения, использованные атрибутами [size_is], [length_is] и другими атрибутами задания размерности массива, не могут быть размещены в вызовах функций. При этом, например, стал бы затруднительным маршалинг строк, соответствие и/или переменная длина которых размещены в вызовах функций wcslen или strlen. Это означает, что такой код в IDL является недопустимым: HRESULT Method24([in, size_is(wcslen(wsz) + 1)] const OLECHAR *wsz); Поскольку это ограничение сделало бы использование строк чрезвычайно неудобным для клиентских программ, IDL поддерживает строковый атрибут, который требует на уровне маршалинга вызывать соответствующую функцию xxxlen для вычисления соответствия массива. Ниже приведено правильное задание строки в качестве входного параметра: HRESULT Method25([in, string] const OLECHAR *wsz); или: HRESULT Method26([in, string] const OLECHAR wsz[]); При использовании строк в качестве выходных или входных/выходных параметров почти всегда целесообразно явно задавать длину буфера вызывающей программы, для гарантии того, что он будет достаточно большим на стороне сервера. Рассмотрим следующий полный ошибок код IDL: HRESULT Method27([in, out, string] OLECHAR *pwsz); Если вызывающая программа запускает этот метод с помощью достаточно короткой строки: void f(IFoo *pFoo) { OLECHAR wsz[1024]; wcscpy(wsz, OLESTR(«Hello»)); pFoo->Method27(wsz); // .. process updated string // .. обрабатываем обновленную строку } то длина массива, размещенного на стороне сервера, будет вычислена, исходя из длины входной строки (эта длина равна шести с учетом заключительного нулевого символа). Рассмотрим следующую реализацию метода со стороны сервера: HRESULT CFoo::Method27(OLECHAR *wsz) { DisplayString(wsz); // wsz only can hold 6 characters! // wsz может хранить только 6 символов! wcscpy(wsz, OLESTR(«Goodbye»)); return S_OK; } Поскольку соответствие массива основывалось на величине wcslen(OLESTR(«Hello»)+1), то, когда реализация метода перезапишет в данную строку что-то более длинное, «хвост» этой строки перезапишет случайное число байтов памяти, что приведет к неисправимым ошибкам (будем надеяться, еще до выпуска данной программы в свет). Это означает, что, хотя вызывающая программа и имела достаточно памяти, заранее выделенной для записи результирующей строки, уровень маршалинга со стороны сервера не знал об этой кажущейся внешней памяти и выделил место, достаточное для хранения только шести символов строки Unicode. Код на IDL должен был быть таким: HRESULT Method28([in] long cchMax, [in, out, string, size_is(cchMax)] OLECHAR *wsz); а вызывающая программа могла бы использовать это так: void f(IFoo *pFoo) { OLECHAR wsz[1024]; wcscpy(wsz, OLESTR(«Hello»)); pFoo->Method28(1024, wsz); // .. process updated string // .. обрабатываем обновленную строку } Наиболее неприятным аспектом примера c [in, out, string] является то, что он прекрасно работает, когда входная строка имеет по крайней мере такую же длину, как выходная строка. Ошибки, связанные с этим методом, будут периодическими и могут ни разу не возникнуть на стадии тестирования проекта. В большинстве обычных API-функций, когда функция возвращает в вызывающую программу данные переменной длины, вызывающая программа заранее выделяет буфер для хранения результатов функции, а реализация функции заполняет буфер, заготовленный вызывающей программой. Ответственность за задание правильного размера буфера лежит на вызывающей программе. При использовании заданных вызывающей программой буферов для возвращения структур данных переменной длины (таких, как строки) может возникнуть проблема. Возможно, реализация метода захочет возвратить больше данных, чем ожидает вызывающая программа. Рассмотрим следующий код Windows SDK, который отображает текст редактирующего управляющего элемента, то есть текстового окна, позволяющего набирать и редактировать текст: void Show(HWND hwndEdit) { TCHAR sz[1024]; GetWindowText(hwndEdit, sz, 1024); MessageBox(0, sz, _TEXT(«Hi!»), MB_OK); } Заметим, что разработчик Show полагает, что редактирующий управляющий элемент никогда не будет содержать больше 1024 символов. Каким образом он или она узнали об этом? Самым точным образом. Можно было бы подумать, что такая реализация была бы надежнее: void Show(HWND hwndEdit) { int cch = GetWindowTextLength(hwndEdit); TCHAR *psz = new TCHAR[cch+1]; GetWindowText(hwndEdit, psz, cch); MessageBox(0, sz, _TEXT(«Hi!»), MB_OK); delete[] psz; } но как в данном примере вызывающая программа может быть уверена, что пользователь не напечатает еще символ после вызова GetWindowTextLength, но до вызова GetWindowText? Тот факт, что размещение основано на потенциально устаревшей информации, делает данную идиому чувствительной к условиям гонки. Предшествующие идиомы программирования, возможно, и годятся для HWND, но совершенно неприменимы для объектов СОМ. В отличие от HWND, к объектам СОМ весьма вероятен одновременный доступ со стороны многих участников. Кроме того, стоимость двух вызовов метода для выполнения одной операции, как показано выше, очень быстро уменьшила бы производительность, особенно в распределенной среде, где задержка, вызванная передачей и приемом пакетов информации, создает огромные проблемы при циклических вызовах метода. В силу этих двух факторов при передаче типов данных с переменной длиной из реализации метода в вызывающую программу через [out]-параметр правильно организованный интерфейс СОМ предписывает реализации метода выделить пространство для результата, используя СОМ-распределитель памяти задачи. Это необходимо, поскольку фактический размер результата может быть известен только внутри реализации метода. Этот динамически выделенный буфер возвращается программе, вызвавшей метод, и после того, как буфер уже не нужен, вызывающая программа должна освободить этот буфер распределителем памяти задачи в вызываемом процессе. Чтобы выразить эту идиому для строкового параметра, приведем следующий корректно работающий код IDL: HRESULT Method29([out, string] OLECHAR **ppwsz); из которого следует такая реализация со стороны сервера: HRESULT CFoo::Method29(OLECHAR **ppwsz) { const OLECHAR wsz[] = OLESTR(«Goodbye»); int cb = (wcslen(wsz) + 1) * sizeof(OLECHAR); *ppwsz = (OLECHAR*)CoTaskMemAlloc(cb); if (*ppwsz == 0) return E_OUTOFMEMORY; wcscpy(*ppwsz, wsz); return S_OK; } Для правильного использования этого метода необходим такой код со стороны клиента: void f(IFoo *pFoo) { OLECHAR *pwsz = 0; if SUCCEEDED(pFoo->Method29(&pwsz)) { DisplayString(pwsz); CoTaskMemFree(pwsz); } } Хотя, с одной стороны, применение этой технологии может привести к избыточному копированию памяти, с другой стороны, уменьшается время на прием-передачу и гарантируется, что могут быть возвращены строки любой длины, причем вызывающей программе не требуется связывать дополнительное пространство буфера в ожидании сколь угодно больших строк. Синтаксис массива, приведенный в этом разделе, является совершенно разумным для программистов на С и C++. К сожалению, в то время, когда пишется этот текст, Visual Basic не способен работать ни с какими массивами переменной длины и может воспринимать только массивы фиксированной длины. Для того чтобы позволить Visual Basic посылать и получать массивы переменной длины, файлы СОМ IDL определяют среди прочих составной тип, именуемый SAFEARRAY. SAFEARRAY – это довольно редко используемая структура данных, которая позволяет передавать в качестве параметров многомерные массивы, совместимые с типом VARIANT. Для определения размеров массива SAFEARRAY в СОМ предусмотрен тип данных SAFEARRAYBOUND: typedef struct tagSAFEARRAYBOUND { ULONG cElements; // size_is for dimension // size_is для размерности LONG lLbound; // min index for dimension (usually 0) // минимальный индекс для размерности (обычно 0) } SAFEARRAYBOUND; Тип данных SAFEARRAY внутри использует совместимый массив типа SAFEARRAYBOUND, чтобы придать некоторую форму содержимому массива: typedef struct tagSAFEARRAY { USHORT cDims; // # of dimensions // число измерений USHORT fFeatures; // flags describing contents // флаги, описывающие содержимое ULONG cbElements; // # of bytes per element // число байтов на элемент ULONG cLocks; // used to track memory usage // применяется для слежения за использованием памяти void* pvData; // actual elements // фактические элементы [size_is(cDims)] SAFEARRAYBOUND rgsabound[] } SAFEARRAY; Приведенный выше IDL в действительности не используется для описания сетевого формата массивов SAFEARRAY, однако он используется для их программного описания. Чтобы обеспечить пользователю максимальную гибкость в вопросах управления памятью, в СОМ определены следующие флаги, которые могут использоваться с полем fFeatures: FADF_AUTO /* array is allocated on the stack */ /* массив размещен в стеке */ FADF_STATIC /* array is statically allocated */ /* массив размещен статически */ FADF_EMBEDDEO /* array is embedded in a structure */ /* массив вложен в структуру */ FADF_FIXEDSIZE /* may not be resized or reallocated */ /* не может изменить размеры или быть перемещен*/ FADF_BSTR /* an array of BSTRs */ /* массив из BSTR */ FADF_UNKNOWN /* an array of IUnknown* */ /* массив из IUnknown* */ FADF_DISPATCH /* an array of IDispatch* */ /* массив из IDispatch* */ FADF_VARIANT /* an array of VARIANTS */ /* массив из VARIANTS */ Для предоставления SAFEARRAY возможности определять типы данных своих элементов, компилятор IDL распознает специальный, специфический для SAFEARRAY, синтаксис: HRESULT Method([in] SAFEARRAY(type) *ppsa); где type – тип элемента в SAFEARRAY. Соответствующий прототип данного метода в C++ выглядел бы примерно так: HRESULT Method(SAFEARRAY **psa); Отметим, что в определении IDL используется только один уровень косвенности; в то же время в соответствующем определении C++ используются два уровня косвенности. Рассмотрим следующее определение на IDL, задающее массив типа SAFEARRAY из коротких целых чисел: HRESULT Method([in] SAFEARRAY(short) *psa); Соответствующее определение на Visual Basic выглядело бы таким образом: Sub Method(ByVal psa As Integer()) Отметим, что в варианте на Visual Basic не указано явно размерностей массива. Напомним, однако, что Visual Basic поддерживает массивы с фиксированной длиной. Тип данных SAFEARRAY поддерживается весьма богатым набором API-функций, которые позволяют изменять размерность массивов и производить обход их содержимого переносимым образом. Для доступа к элементам типа SAFEARRAY СОМ предусматривает следующие вызовы API-функций: // get a pointer to the actual array elements // получаем указатель на фактически элементы массива HRESULT SafeArrayAccessData([in] SAFEARRAY *psa, [out] void ** ppv); // release pointer returned by SafeArrayAccessData // освобождаем указатель, возвращенный функцией SafeArrayAccessData HRESULT SafeArrayUnaccessData([in] SAFEARRAY *psa); // Get number of dimensions // Получаем количество измерений ULONG SafeArrayGetDim([in] SAFEARRAY *psa); // Get upper bound of a dimension // Получаем верхнюю границу измерения HRESULT SafeArrayGetUBound([in] SAFEARRAY *psa, [in] UINT nDim, [out] long *pUBound); // Get lower bound of a dimension // Получаем нижнюю границу измерения HRESULT SafeArrayGetLBound([in] SAFEARRAY *psa, [in] UINT nDim, [out] long *pLBound); Эти методы обеспечивают компактный и надежный способ доступа к текущему содержимому массива. Рассмотрим следующий код на IDL: HRESULT Sum([in] SAFEARRAY(long) *ppsa, [out, retval] long *pSum); Тогда следующая реализация метода будет вычислять сумму элементов массива типа SAFEARRAY, состоящего из длинных целых чисел (long integers): STDMETHODIMP MyClass::Sum(SAFEARRAY **ppsa, long *pnSum) { assert(ppsa && *ppsa && pnSum); assert(SafeArrayGetDim(*ppsa) == 1); long iUBound, iLBound; // note that dimension indices are one-based // отметим, что индексы размерности начинаются с единицы HRESULT hr = SafeArrayGetUBound(*ppsa, 1, &iUBound); assert(SUCCEEDED(hr)); hr = SafeArrayGetLBound(*ppsa, 1, &iLBound); assert(SUCCEEDED(hr)); long *prgn = 0; hr = SafeArrayAccessData(*ppsa, (void**)&prgn); *pnSum = 0; for (long i = 0; i < iUBound – iLBound; i++) *pnSum += prgn[i]; SafeArrayUnaccessData(*ppsa); return S_OK; } Отметим, что вызовы любых API-функций, которые имеют дело с размерностями массива, используют индексы, начинающиеся с единицы. Приведенный выше фрагмент кода просто манипулировал содержимым существующего SAFEARRAY-массива. Для создания одномерного массива типа SAFEARRAY для передачи его в качестве параметра метода в СОМ имеется следующая API-функция, которая выделяет память для структуры SAFEARRAY и элементов этого массива в одном непрерывном блоке памяти: SAFEARRAY *SafeArrayCreateVector( [in] VARTYPE vt, // element type // тип элемента [in] long iLBound, // index of lower bound // индекс нижней границы [in] unsigned int cElems); // # of elements // число элементов Кроме того, в СОМ имеются различные функции, предназначенные для размещения многомерных массивов, однако их рассмотрение выходит за рамки данной дискуссии. При таком определении метода на IDL: HRESULT GetPrimes([in] long nStart, [in] long nEnd, [out] SAFEARRAY(long) *ppsa); следующее определение метода на C++ возвращает вызывающей программе массив типа SAFEARRAY, размещенный в вызываемом методе: STDMETHODIMP MyClass::GetPrimes (long nMin, long nMax, SAFEARRAY **ppsa) { assert(ppsa); UINT cElems = GetNumberOfPrimes(nMin, nMax); *ppsa = SafeArrayCreateVector(VT_I4, 0, cElems); assert(*ppsa); long *prgn = 0; HRESULT hr = SafeArrayAccessData(*ppsa, (void**)&prgn); assert(SUCCEEDED(hr)); for (UINT i=0; i < cElems; i++) prgn[i] = GetNextPrime(i ? prgn[1 – 1] : nMin); SafeArrayUnaccessData(*ppsa); return S_OK; } Соответствующий код с клиентской стороны выглядел бы на Visual Basic примерно так: Function GetSumOfPrimes(ByVal nMin as Long, ByVal nMax as Long) as Long Dim arr() as Long Dim n as Variant Objref.GetPrimes nMin, nMax, arr GetSumOfPrimes = 0 for each n in arr GetSumOfPrimes = GetSumOfPrimes + n Next n End Function что соответствует следующему коду на C++: long GetSumOfPrimes (long nMin, long nMax) { SAFEARRAY *pArray = 0; HRESULT hr = g_pObjRef->GetPrimes(nMin, nMax, &pArray); assert(SUCCEEDED(hr) && SafeArrayGetDim(pArray) == 1); long *prgn = 0; hr = SafeArrayAccessData(pArray, (void**)&prgn); long iUBound, iLBound, result = 0; SafeArrayGetUBound(pArray, 1, &iUBound); SafeArrayGetLBound(pArray, 1, &iLBound); for (long n = iLBound; n <= iUBound: n++) result += prgn[n]; SafeArrayUnaccessData(pArray); SafeArrayDestroy(pArray); return n; } Отметим, что вызывающая программа ответственна за освобождение ресурсов, выделенных для SAFEARRAY-массива, возвращенного как [out]-параметр. Вызов функции SafeArrayDestroy корректно освобождает всю память и все ресурсы, удерживаемые структурой SAFEARRAY. Управление потоками данныхОтметим, что в предыдущих примерах использования массивов, в том числе типа SAFEARRAY , вопрос о том, какое количество данных будет передано в ORPC-сообщении, решал отправитель данных. Рассмотрим следующее простое определение метода на IDL: HRESULT Sum([in] long cElems, [in, size_is(cElems)] double *prgd, [out, retval] double *pResult); Если бы вызывающая программа должна была запустить этот метод следующим образом: double rgd[1024 * 1024 * 16]; HRESULT hr = p->Sum(sizeof(rgd)/sizeof(*rgd), rgd); то размер результирующего ответного сообщения ORPC-запроса был бы не меньше 128 Мбайт. Хотя лежащий в основе RPC-протокол вполне в состоянии разбивать большие сообщения на несколько сетевых пакетов, при использовании больших массивов все же возникают некоторые проблемы. Одна очевидная проблема состоит в том, что вызывающая программа должна иметь свыше 128 Мбайт доступной памяти сверх той, которая занята существующим массивом. Дублирующий буфер необходим интерфейсному заместителю для создания ответного ORPC-сообщения, в которое в конечном счете будет скопирован этот массив. Подобная проблема заключается в том, что процесс объекта также должен иметь больше 128 Мбайт доступной памяти для реконструирования полученных RPC-пакетов в единое сообщение ORPC. Если бы массив использовал атрибут [length_is], то следовало бы выделить еще 128 Мбайт, чтобы скопировать этот массив в память для передачи его методу. Эта проблема относится к параметрам как типа [in], так и [out]. В любом случае отправитель массива может иметь достаточное буферное пространство для создания OPRC-сообщения, а получатель массива – нет. Данная проблема является результатом того, что получатели не имеют механизма для управления потоками на уровне приложений. Более сложная проблема с приведенным выше определением метода связана со временем ожидания (latency). Семантика ORPC-запроса требует, чтобы на уровне RPC/ORPC полное ORPC-сообшение реконструировалось до вызова метода объекта. Это означает, что объект не может начать обработку имеющихся данных, пока не получен последний пакет. Когда общее время передачи большого массива довольно велико, объект будет оставаться незанятым в течение значительного промежутка времени, ожидая получения последнего пакета. Возможно, что в течение этого времени ожидания многие элементы уже успешно прибыли в адресное пространство объекта; тем не менее, семантика вызова метода в СОМ требует, чтобы к началу текущего вызова присутствовали все элементы. Та же проблема возникает, когда массивы передаются как параметры с атрибутом [out], так как клиент не может начать обработку тех частичных результатов операции, которые, возможно, уже получены к этому моменту. Для решения проблем, связанных с передачей больших массивов в качестве параметров метода, в СОМ имеется стандартная идиома разработки интерфейсов, позволяющая получателю данных явно осуществлять управление потоками элементов массива. Эта идиома основана на передаче вместо фактических массивов специального интерфейсного указателя СОМ. Этот специальный интерфейсный указатель, называемый нумератором (enumerator), позволяет извлекать элементы из отправителя со скоростью, подходящей для получателя. Чтобы применить эту идиому к приведенному выше определению метода, понадобится следующее определение интерфейса: interface IEnumDouble : Unknown { // pull a chunk of elements from the sender // извлекаем порцию данных из отправителя HRESULT Next([in] ULONG cElems, [out, size_is(cElems), length_is(*pcFetched)] double *prgElems, [out] ULONG *pcFetched); // advance cursor past cElems elements // переставляем курсор после элементов cElems HRESULT Skip([in] cElems); // reset cursor to first element // возвращаем курсор на первый элемент HRESULT Reset(void); // duplicate enumerator's current cursor // копируем текущий курсор нумератора HRESULT Clone([out] IEnumDouble **pped); } Важно отметить, что интерфейс IEnum моделирует только курсор, а отнюдь не текущий массив. Имея такое определение интерфейса, исходное определение метода IDL: HRESULT Sum([in] long cElems, [in, size_is(cElems)] double *prgd, [out, retval] double *pResult); преобразуется следующим образом: HRESULT Sum([in] IEnumDouble *ped, [out, retval] double *pResult); Отметим, что подсчет элементов больше не является обязательным, так как получатель данных обнаружит конец массива, когда метод IEnumDouble::Next возвратит специальный HRESULT (S_FALSE ). При наличии приведенного выше определения интерфейса корректной была бы следующая реализация метода: STDMETHODIMP MyClass::Sum(IEnumDouble *ped, double *psum) { assert(ped && psum); *psum = 0; HRESULT hr; do { // declare a buffer to receive some elements // объявляем буфер для получения нескольких элементов enum { CHUNKSIZE = 2048 }; double rgd[CHUNKSIZE]; // ask data producer to send CHUNKSIZE elements // просим источник данных послать CHUNKSIZE элементов ULONG cFetched; hr = ped->Next(CHUNKSIZE, rgd, &cFetched); // adjust cFetched to address sloppy objects // настраиваем cFetched на исправление некорректных объектов if (hr == S_OK) cFetched = CHUNKSIZE; if (SUCCEEDED(hr)) // S_OK or S_FALSE // S_OK или S_FALSE // consume/use received elements // потребляем/используем полученные элементы for (ULONG n = О; п < cFetched; n++) *psum += rgd[n]; } while (hr == S_OK); // S_FALSE or error terminates // завершается по S_FALSE или по ошибке } Отметим, что подпрограмма Next возвратит S_OK в случае, если у отправителя имеются дополнительные данные для посылки, и S_FALSE , если пересылка закончена. Также отметим, что в данный код включена защита от некорректных реализации, которые не утруждают себя установкой переменной cFetched при возвращении S_OK (S_OK означает, что все запрошенные элементы были извлечены). Одно из преимуществ использования идиомы IEnum состоит в том, что она позволяет отправителю откладывать генерирование элементов массива. Рассмотрим следующее определение метода на IDL: HRESULT GetPrimes([in] long nMin, [in] long nMax, [out] IEnumLong **ppe); Разработчик объекта может создать специальный класс, который генерирует по требованию простые числа и реализует интерфейс IEnumLong: class PrimeGenerator : public IEnumLong { LONG m_cRef; // СОМ reference count // счетчик ссылок СОМ long m_nCurrentPrime; // the cursor // курсор long m_nMin; // minimum prime value // минимальное значение простого числа long m_nMax; // maximum prime value // максимальное значение простого числа public: PrimeGenerator(long nMin, long nMax, long nCurrentPrime) : m_cRef(0), m_nMin(nMin), m_nMax(nMax), m_nCurrentPrime(nCurrentPrime) { } // IUnknown methods // методы IUnknown STDMETHODIMP QueryInterface(REFIID riid, void **ppv); STDHETHODIMP_(ULONG) AddRef(void); STDMETHODIMP_(ULONG) Release(void); // IEnumLong methods // методы IEnumLong STDMETHODIMP Next(ULONG, long *, ULONG *); STDMETHODIMP Skip(ULONG); STDMETHODIMP Reset(void); STDMETHODIMP Clone(IEnumLong **ppe); }; Реализация генератора Next будет просто порождать запрошенное количество простых чисел: STDMETHODIMP PrimeGenerator::Next(ULONG cElems, long *prgElems, ULONG *pcFetched) { // ensure that pcFetched is valid if cElems > 1 // удостоверяемся, что pcFetched легален, если cElems больше единицы if (cElems > 1 && pcFetched == 0) return E_INVALIDARG; // fill the buffer // заполняем буфер ULONG cFetched = 0; while (cFetched < cElems && m_nCurrentPrime <= m_nMax) { prgElems[cFetched] = GetNextPrime(m_nCurrentPrime); m_nCurrentPrime = prgElems[cFetchcd++]; } if (pcFetched) // some callers may pass NULL // некоторые вызывающие программы могут передавать NULL *pcFetched = cFetched; return cFetched == cElems ? S_OK : S_FALSE; } Отметим, что даже если имеются миллионы допустимых значений, одновременно в памяти будет находиться лишь малое их число. Методу генератора Skip нужно просто генерировать и отбрасывать запрошенное количество элементов: STDMETHODIMP PrimeGenerator::Skip(ULONG cElems) { ULONG cEaten = 0; while (cEaten < cElems && m_nCurrentPrime <= m_nMax) { m_nCurrentPrime = GetNextPrime(m_nCurrentPrime); cEaten++; } return cEaten == cElems ? S_OK : S_FALSE; } Метод Reset устанавливает курсор на начальное значение: STDMETHODIMP PrimeGenerator::Reset(void) { m_nCurrentPrime = m_nMin; return S_OK; } а метод Clone создает новый генератор простых чисел на основе минимума, максимума и текущих значений, выданных существующим генератором: STDMETHODIMP PrimeGenerator::Clone(IEnumLong **ppe) { assert(ppe); *рре = new PrimeGenerator(m_nMin, m_nMax, m_nCurrent); if (*ppe) (*ppe)->AddRef(); return S_OK; } При наличии реализации PrimeGenerator реализация метода GetPrimes текущим объектом становится тривиальной: STDMETHODIMP MyClass::GetPrimes(long nМin, long nMax, IEnumLong **ppe) { assert(ppe); *ppe = new PrimeGenerator (nMin, nMax, nMin); if (*ppe) (*ppe)->AddRef(); return S_OK; } Большая часть этой реализации находится теперь в классе PrimeGenerator, а не в классе объекта. Динамический вызов в сравнении со статическимДо сих пор говорилось о том, что СОМ основан на клиентских программах, имеющих на этапе разработки предварительную информацию об определении интерфейса. Это достигается либо через заголовочные файлы C++ (для клиентов C++), либо через библиотеки типов (для клиентов Java и Visual Basic). В общем случае это не представляет трудностей, так как программы, написанные на этих языках, перед употреблением обычно проходят фазу какой-либо компиляции. Некоторые языки не имеют такой фазы компиляции на этапе разработки и вместо этого распространяются в исходном коде с тем, чтобы интерпретироваться во время выполнения. Вероятно, наиболее распространенными среди таких языков являются языки сценариев на базе HTML (например, Visual Basic Script, JavaScript), которые выполняются в контексте Web-броузера или Web-сервера. В обоих этих случаях текст сценариев вкладывается в его исходном виде в файл HTML, а окружающая исполняемая программа выполняет текст сценариев «на лету», по мере анализа HTML. С целью обеспечить разнообразную среду программирования эти окружения позволяют сценариям вызывать методы СОМ-объектов, которые могут создаваться в самом тексте сценария или где-нибудь еще в HTML-потоке (например, какой-либо управляющий элемент, который является также частью Web– страницы). В таких средах в настоящее время невозможно использовать библиотеки типов или другие априорные средства для снабжения машины времени выполнения (runtime engine) описанием используемых интерфейсов. Это означает, что объекты сами должны помогать интерпретатору переводить исходный текст сценариев в содержательные вызовы методов. Для того чтобы объекты быть использованы из интерпретирующих сред типа Visual Basic Script и JavaScript, СОМ определяет интерфейс, выражающий функциональность интерпретатора. Этот интерфейс называется IDispatch и определяется следующим образом: [object, uuid(00020400-0000-0000-C000-000000000046)] interface IDispatch : IUnknown { // structure to model a list of named parameters // структура для моделирования списка именованных параметров typedef struct tagDISPPARAMS { [size_is(cArgs)] VARIANTARG * rgvarg; [size_is(cNamedArgs)] DISPID * rgdispidNamedArgs; UINT cArgs; UINT cNamedArgs; } DISPPARAMS; // can the object describe this interface? // может ли объект описать этот интерфейс? HRESULT GetTypeInfoCount([out] UINT * pctinfo); // return a locale-specific description of this interface // возвращаем специфическое для данной локализации описание этого интерфейса HRESULT GetTypeInfo( [in] UINT itInfo, // reserved, m.b.z. // зарезервировано, должно равняться нулю [in] LCID lcid, // locale ID // код локализации [out] ITypeInfo ** ppTInfo); // put it here! // помещаем это здесь! // resolve member/parameter names to DISPIDs // преобразовываем имена членов/параметров в DISPID HRESULT GetIDsOfNames( [in] REFIID riid, // reserved, must be IID_NULL // зарезервировано, должно равняться IID_NULL [in, size_is(cNames)] LPOLESTR * rgszNames, // method+params // метод + параметры [in] UINT cNames, // count of names // количество имен [in] LCID lcid, // locale ID // локальный ID [out, size_is(cNames)] DISPID * rgid // tokens of names // маркеры имен ); // access member via its DISPID // обращаемся к члену через его DISPID HRESULT Invoke( [in] DISPID id, // token of member // маркер члена [in] REFIID riid, // reserved, must be IID_NULL // зарезервировано, должно равняться IID_NULL [in] LCID lcid, // locale ID // локальный ID [in] WORD wFlags, // method, propput, or propget? // метод propput или propget? [in,out] DISPPARAMS * pDispParams, // logical parameters // логические параметры [out] VARIANT * pVarResult, // logical result // логический результат [out] EXCEPINFO * pExcepInfo, // IErrorInfo params // параметры IErrorInfo [out] UINT * puArgErr // used for type errors // использовано для ошибок типа ); Когда машина сценариев впервые пытается обратиться к объекту, она использует QueryInterface для запроса интерфейса IDispatch этого объекта. Если объект отклоняет запрос QueryInterface, то машина сценариев этот объект использовать не может. Если же объект успешно возвращает свой интерфейс IDispatch машине сценариев, то машина будет использовать метод GetIDsOfNames этого объекта для перевода имен методов и свойств в маркеры. Эти маркеры формально называются DISPID и являются эффективно синтаксически разобранными (parsed) целыми числами, которые единственным образом идентифицируют свойство или метод. После преобразования имени метода или свойства в маркер машина сценариев потребует запуска именованного метода/свойства через метод IDispatch::Invoke данного объекта. Отметим, что поскольку IDispatch::Invoke принимает значения параметров операции в виде массива именованных типов VARIANT с использованием структуры DISPPARAMS, то диапазон поддерживаемых типов параметров ограничен возможностью записи в один VARIANT. Интерфейсы на базе IDispatch (часто называемые dispinterface – диспинтерфейс, или диспетчерский интерфейс ) логически эквивалентны обычному интерфейсу СОМ. Основное различие состоит в методах вызова на практике логических операций интерфейса. В случае обычного интерфейса СОМ вызовы методов основываются на статике, на априорном знании сигнатуры методов интерфейса. В случае диспинтерфейса вызовы методов основаны на текстовых представлениях ожидаемой сигнатуры вызовов методов. Если вызывающая программа правильно угадывает сигнатуру метода, то вызов может быть правильно диспетчеризован. Если же вызывающая программа неправильно угадывает сигнатуру метода, то диспетчеризовать вызов, возможно, не удастся. Если для параметров метода используются неверные типы данных, то преобразование их в нужные является делом объекта (если это вообще возможно). Простейший способ выразить диспинтерфейс на IDL – это использовать ключевое слово dispinterface: [uuid(75DA6450-DD0F-11d0-8C58-0880C73925BA)] dispinterface DPrimeManager { properties: [id(1), readonly] long MinPrimeOnMachine; [id(2)] long MinPrime; methods: [id(3)] long GetNextPrime([in] long n); } Этот синтаксис вполне читабелен; однако он предполагает, что вызывающая программа будет всегда обращаться к свойствам и методам объекта через IDispatch. История показала, что по мере развития программных сред этапа разработки и выполнения они часто становятся способными использовать обычные интерфейсы СОМ. Для обеспечения того, чтобы обращение к диспинтерфейсу было успешным и в будущих средах подготовки сценариев, как правило, лучше моделировать интерфейс как двойственный, или дуальный (dual interface). Двойственные интерфейсы являются обычными интерфейсами СОМ, наследующими от IDispatch. Поскольку IDispatch является базовым интерфейсом, то он абсолютно совместим с полностью интерпретируемыми клиентами сценариев. В то же время этот интерфейс совместим вверх со средами, которые могут непосредственно связываться со статически определенным интерфейсом СОМ. Ниже приведено IDL-определение для двойственного варианта интерфейса DPrimeManager: [object, dual, uuid(75DA6450-DD0F-11d0-8C58-0080C73925BA)] interface DIPrimeManager : IDispatch { [id(1), propget] HRESULT MinPrimeOnMachine( [out, retval] long *pval); [id(2), propput] HRESULT MinPrime([in] longval); [id(2), propget] HRESULT MinPrime([out, retval] long *pval); [id(3)] long GetNextPrime([in] long n); } Заметим, что этот интерфейс наследует IDispatch, а не IUnknown. Также отметим, что данный интерфейс имеет атрибут [dual] . Этот атрибут заставляет сгенерированную библиотеку типов включить в себя диспетчерский вариант интерфейса, который совместим со средами, не поддерживающими двойственные интерфейсы. Атрибут [dual] относится к категории атрибутов [oleautomation] и также заставляет сгенерированную библиотеку типов добавлять ключи реестра для универсального маршалера во время выполнения RegisterTypeLib. Если интерфейс определен как двойственный, то реализация методов IDispatch является тривиальной. Дело в том, что синтаксический анализатор библиотеки типов реализует два из четырех методов IDispatch . Если двойственный интерфейс был определен заранее, объекту необходимо на этапе инициализации просто загрузить библиотеку типов: class PrimeManager: DIPrimeManager { LONG m_cRef; // СОМ reference count // счетчик ссылок СОМ ITypeInfo *m_pTypeInfo; // ptr. to type desc. // указатель на описание типов // IUnknown methods… // методы IUnknown… // IDispatch methods… // методы IDispatch… // IPrimeManager methods… // методы IPrimeManager… PrimeManager(void) : m_cRef(0) { ITypeLib *ptl = 0; HRESULT hr = LoadRegTypeLib(LIBID_PrimeLib, 1, 0, 0, &ptl); assert(SUCCEEDED(hr)); hr = ptl->GetTypeInfoOfGuid(IID_DIPrimeManager, &m_pTypeInfo); ptl->Release(); } virtual PrimeManager(void) { m_pTypeInfo->Release(); } }; Имея приведенное выше определение класса, метод GetTypeInfo просто возвращает описание данного интерфейса: STDMETHODIMP PrimeManager::GetTypeInfo (UINT it, LCID lcid, ITypeInfo **ppti) { assert(it == 0 && ppti != 0); (*ppti = m_pTypeInfo)->AddRef(); return S_OK; } Если бы объект поддерживал несколько локализованных библиотек типов, то реализации следовало бы использовать параметр LCID, чтобы решить, какое описание типа нужно возвратить. Соответствующая реализация GetTypeInfoCount еще проще: STDMETHODIMP PrimeManager::GetTypeInfoCount(UINT *pit) { assert(pit != 0); *pit = 1; // only 0 or 1 are allowed // допускаются только 0 или 1 return S_OK; } Единственными допустимыми значениями счетчика являются нуль (это означает, что данный объект не содержит описаний своего интерфейса) и единица (это означает, что данный объект содержит описания своего интерфейса). Даже если объект поддерживает несколько локализованных описаний типа, результирующий счетчик остается равным единице. Методы GetTypeInfo и GetTypeInfoCount фактически являются вспомогательными. Истинным ядром интерфейса IDispatch являются методы GetIDsOfNames и Invoke. Реализация GetIDsOfNames направляет вызов в машину синтаксического анализа библиотеки типов, встроенную в СОМ: STDMETHODIMP PrimeManager::GetIDsOfNames(REFIID riid, OLECHAR **pNames, UINT cNames, LCID lcid, DISPID *pdispids) { assert(riid == IID_NULL); return m_pTypeInfo->GetIDsOfNames(pNames, cNames, pdispids); } Поскольку библиотека типов содержит все имена методов и соответствующие им DISPID , реализация не представляет труда для синтаксического анализатора. Метод Invoke реализован аналогичным образом: STDMETHODIMP PrimeManager::Invoke(DISPID id, REFIID riid, LCID lcid, WORD wFlags, DISPPARAMS *pd, VARIANT *pVarResult, EXCEPINFO *pe, UINT *pu) { assert(riid == IID_NULL); void *pvThis = static_cast<DIPrimeManager*>(this); return m_pTypeInfo->Invoke(pvThis, id, wFlags, pd, pVarResult, pe, pu); }  Первым параметром ITypeInfo::Invoke является указатель на интерфейс. Тип этого интерфейса должен быть таким же, как интерфейс, который описан в информации о типах. Когда передаваемые аргументы корректно синтаксически преобразованы в стек вызова (call stack), синтаксический анализатор будет вызывать текущие методы через этот интерфейсный указатель. Рис. 7.6 иллюстрирует последовательность вызовов для сред подготовки сценариев, которые осуществляют вызовы через двойственные интерфейсы. Двунаправленные интерфейсные контрактыКак было показано в главе 5, объекты, постоянно находящиеся в различных апартаментах, могут использовать сервисные программы друг друга вне зависимости от того, резидентом какого апартамента является другой объект. Поскольку удаленный доступ в СОМ основан на концепции апартаментов, разработчикам необходимо рассматривать процессы не как клиенты или серверы в чистом виде, а скорее как набор из одного или нескольких апартаментов, которые способны одновременно экспортировать и импортировать интерфейсы. Как два объекта договариваются о том, чьи интерфейсы будут использоваться для взаимного сотрудничества, в значительной степени является спецификой области применения. Для примера рассмотрим следующий интерфейс, моделирующий программиста: [uuid(75DA6457-DD0F-11d0-8C58-0080C73925BA),object] interface IProgrammer : IUnknown { HRESULT StartHacking(void); HRESULT IsProductDone([out, retval] BOOL *pbIsDone); } Клиент будет использовать такой интерфейс следующим образом: HRESULT ShipSoftware(void) { IProgrammer *pp = 0; HRESULT hr = CoGetObject(OLESTR(«programmer:Bob»), 0, IID_IProgrammer, (void**)&pp); if (SUCCEEDED(hr)) { hr = pp->StartHacking(); BOOL bIsDone = FALSE; while (!bIsDone && SUCCEEDED(hr)) { Sleep(15000); // wait 15 seconds // ожидаем 15 секунд hr = pp->IsProductDone(&bIsDone); // check status // проверяем состояние } pp->Release(); } } Очевидно, что этот код весьма неэффективен, поскольку клиент каждые 15 секунд опрашивает состояние объекта. Более эффективным для клиента был бы следующий подход: подготовить второй объект, которому объект-программист (programmer object) мог бы сообщить, когда данный объект придет в нужное состояние. Этот подготовленный клиентом объект должен экспортировать интерфейс, предоставляющий контекст, через который мог бы работать объект-программист: [uuid(75DA6458-DD9F-11d0-8C58-0080C73925BA),object] interface ISoftwareConsumer : IUnknown { HRESULT OnProductIsDone(void); HRESULT OnProductWillBeLate([in] hyper nMonths); } При таком парном определении интерфейса должен существовать некий механизм для информирования объекта-программиста о том, что у клиента имеется реализация ISoftwareConsumer, с помощью которой он может получать уведомления от объекта-программиста об изменениях состояния. Одной из распространенных методик является определение IProgrammer таким образом, чтобы он имел явные методы, через которые клиенты могли бы связываться со своими объектами-потребителями (consumer object). Канонической формой этой идиомы является включение метода Advise: interface IProgrammer : IUnknown { HRESULT Advise ([in] ISoftwareConsumer *psc, [out] DWORD *pdwCookie); : : : посредством которого клиент подготавливает парный объект-потребитель, а программист возвращает DWORD для подтверждения связи. Затем этот DWORD можно было бы использовать в соответствующем методе Unadvise: interface IProgrammer : IUnknown { : : : HRESULT Unadvise([in] DWORD dwCookie); } для того, чтобы сообщить объекту-программисту о прерывании связи. При использовании уникальных DWORD для представления связи программист-потребитель дизайн интерфейса позволяет произвольному числу потребителей независимо друг от друга соединяться с объектом и отсоединяться от него. Если эти два метода имеются в интерфейсе IProgrammer, то реализация программиста может быть соединена с объектом-потребителем с помощью метода Advise STDMETHODIMP Programmer::Advise(ISoftwareConsumer *pcs, DWORD *pdwCookie) { assert(pcs); if (m_pConsumer != 0) // is there already a consumer? // уже есть потребитель? return E_UNEXPECTED; (m_pConsumer = pcs)->AddRef(); // hold onto new consumer // соединяемся с новым потребителем *pdwCookie = DWORD(pcs); // make up a reasonable cookie // готовим подходящий маркер return S_OK; } Соответствующая реализация метода Unadvise выглядела бы примерно так: STDMETHODIMP Programmer::Unadvise(DWORD dwCookie) { // does the cookie correspond to the current consumer? // соответствует ли маркер данному потребителю? if (DWORD(m_pConsumer) != dwCookie) return E_UNEXPECTED; (m_pConsumer)->Release(); // release current consumer // освобождаем текущего потребителя m_pConsumer = 0; return S_OK; } Взаимоотношения между программистом и потребителем показаны на рис. 7.7. Хотя в данной реализации в каждый момент предусмотрен только один потребитель, возможно, что более опытный программист смог бы оперировать несколькими потребителями одновременно, управляя динамическим массивом интерфейсных указателей из ISoftwareConsumer.  Имея приведенную выше реализацию, метод программиста StartHacking может теперь использовать потребителя для индикации готовности результата: STDMETHODIMP Programmer::StartHacking (void) { assert(m_pConsumer); // preemptively notify of lateness // приоритетно сообщаем о задержке HRESULT hr = m_Consumer->OnProductWillBeLate(3); if (FAILED(hr)) return PROGRAMMER_E_UNREALISTICCONSUMER; // generate some code // генерируем некоторый код extern char *g_rgpszTopFiftyStatements[]; for (int n = 0; n < 100000; n++) printf(g_rgpszTopFiftyStatements[rand() % 50]); // inform consumer of done-ness // извещаем потребителя о выполнении hr = m_pConsumer->OnProductIsDone(); return S_OK; } To обстоятельство, что реализация ISoftwareConsumer может принадлежать к другому апартаменту, чем объект-программист, не является существенным. На самом деле метод StartHacking может быть вызван из того апартамента, который содержит объект-потребитель, и в этом случае будет осуществлено повторное вхождение в апартамент вызывающей программы, что, в сущности, является синхронным обратным вызовом. В то время как эта реализация делает вложенные вызовы на объект-потребитель, объект-программист может также в будущем производить вызовы методов объекта-потребителя в любое время. Эта привилегия остается до тех пор, пока не последует вызов метода Unadvise, разрывающий соединение. Поскольку интерфейсы IProgrammer и ISoftwareConsumer, вероятно, были созданы в тандеме для совместной работы, использование явного метода интерфейса IProgrammer для установления связи становится частью протокола при работе с объектами-программистами и является вполне целесообразным. Тот факт, что реализации программиста способны использовать один или несколько объектов-потребителей, может быть документирован как часть протокола интерфейса IProgrammer в порядке уточнения семантического контракта IProgrammer. Существуют, однако, сценарии, в которых интерфейсы совместной работы и обратного вызова разработаны так, что они находятся вне области видимости любого другого интерфейса. Ниже приведен пример такого интерфейса: [uuid(75DA645D-DD0F-11d0-8C58-0080C73925BA),object ] interface IShutdownNotify : IUnknown { HRESULT OnObjectDestroyed([in] IUnknown *pUnk); } В этом интерфейсе предполагается, что разработчик IShutdownNotify заинтересован в получении сообщений о прекращении работы от других объектов. В данном определении, однако, не приведен механизм, с помощью которого эти заинтересованные стороны могли бы сообщить объектам, что они хотели бы быть уведомлены об уничтожении этого объекта. Как показано на рис. 7.8, одна из возможных стратегий осуществления этого состоит в определении второго (парного) интерфейса, который объекты могли бы реализовать: [uuid(75DA645E-DD0F-11d0-8C58-0080C73925BA), object] interface IShutdownSource : IUnknown { HRESULT Advise([in] IShutdownNotify *psn, [out] DWORD *pdwCookie); HRESULT Unadvise([in] DWORD dwCookie); }  Данный интерфейс существует, однако, только для того, чтобы дать наблюдателям (observers) возможность соединить свои интерфейсы IShutdownNotify с объектом. Если имеется большое число типов интерфейсов обратного вызова, то необходимо определить столь же большое число соответствующих интерфейсов только для управления соединением. Ясно, что должен существовать более общий механизм: вхождение в точках стыковки. Точки стыковки являются идиомой СОМ, предназначенной для регистрации связи интерфейсов обратного вызова с объектом и ее отмены. Точки стыковки не являются необходимыми для создания сетей из объектов с большим количеством соединений. К тому же точки стыковки не обеспечивают двунаправленных соединений. Вместо этого идиома точек стыковки выражает общую концепцию регистрации экспортируемых интерфейсов как небольшого числа интерфейсов стандартной инфраструктуры. Наиболее фундаментальным из этих интерфейсов является IConnectionPoint: [object, uuid(B196B286-BAB4-101A-B69C-00AA00341D07)] interface IConnectionPoint : IUnknown { // which type of interface can be connected // какой тип интерфейса можно присоединить HRESULT GetConnectionInterface( [out] IID * pIID); // get a pointer to identity of «real» object // получаем указатель на копию «реального» объекта HRESULT GetConnectionPointContainer([out] IConnectionPointContainer ** ppCPC); // hold and use pUnkSink until notified otherwise // сохраняем и используем pUnkSink, пока не объявлено другое HRESULT Advise([in] IUnknown * pUnkSink, [out] DWORD * pdwCookie); // stop holding/using the pointer associated with dwCookle // прекращаем хранение/использование указателя, связанного с dwCookie HRESULT Unadvise([in] DWORD dwCookie); // get information about currently held pointers // получаем информацию об имеющихся в данный момент указателях HRESULT EnumConnections([out] IEnumConnections ** ppEnum); } Как показано на рис. 7.9, объекты представляют отдельную реализацию этого интерфейса каждому типу интерфейса, который может быть использован объектом в качестве интерфейса обратного вызова. Ввиду того, что IConnectionPoint не выставлен как часть единицы идентификации объекта, он не может быть обнаружен посредством QueryInterface. Вместо этого в СОМ предусмотрен второй интерфейс, который выставлен как часть единицы идентификации объекта, которая позволяет клиентам запрашивать реализацию IConnectionPoint, соответствующую отдельному типу интерфейса обратного вызова: [object,uuid(B196B284-BAB4-101A-B69C-00AA00341D07)] interface IConnectionPointContainer : IUnknown { // get all possible IConnectionPoint implementations // получаем все возможные реализации IConnectionPoint HRESULT EnumConnectionPoints([out] IEnumConnectionPoints ** ppEnum); // get the IConnectionPoint implementation for riid // получаем реализацию IConnectionPoint для riid HRESULT FindConnectionPoint([in] REFIID riid, [out] IConnectionPoint ** ppCP); } 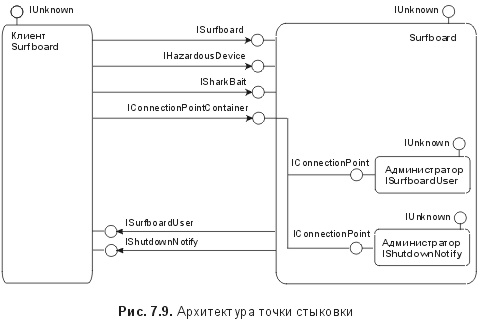 Как показано на рис. 7.9, каждая реализация IConnectionPoint выставляется из отдельной СОМ-единицы идентификации. С учетом вышеупомянутых определений интерфейса клиент мог бы связать свою реализацию IShutdownNotify с объектом следующим образом: HRESULT HookupShutdownCallback(IUnknown *pUnkObject, IShutdownNotify *pShutdownNotify, DWORD &rdwCookie) { IConnectionPointContainer *pcpc = 0; HRESULT hr = pUnkObject->QueryInterface(IID_IConnectionPointContainer, (void**)&pcpc); if (SUCCEEDED(hr)) { IConnectionPoint *pcp = 0; hr =pcpc->FindConnectionPoint(IID_IShutdownNotify,&pcp); if (SUCCEEDED(hr)) { hr = pcp->Advise(pShutdownNotify, &rdwCookie); pcp->Release(); } pcpc->Release(); } } Соответствующий код для разрыва связи выглядит так: HRESULT TeardownShutdownCallback(IUnknown *pUnkObject, DWORD dwCookie) { IConnectionPointContainer *pcpc = 0; HRESULT hr = pUnkObject->QueryInterface(IID_IConnectionPointContainer, (void**)&pcpc); if (SUCCEEDED(hr)) { IConnectionPoint *pcp = 0; hr =pcpc->FindConnectionPoint(IID_IShutdownNotify,&pcp); if (SUCCEEDED(hr)) { hr = pcp->Unadvise(dwCookie); pcp->Release(); } pcpc->Release(); } } Отметим, что в обоих примерах клиент использует метод IConnectionPointContainer::FindConnectionPoint для вызова из объекта его IShutdownNotify-реализации IConnectionPoint. Если объект отклоняет вызов FindConnectionPoint, это говорит о том, что он не понимает семантику интерфейса IShutdownNotify. Это оберегает пользователя от прикрепления произвольных интерфейсов обратного вызова к объекту без полного согласия на это разработчика объекта. Как и в случае с IUnknown, реализации IConnectionPointContainer и IConnectionPoint в значительной степени типичны. Объекту C++ требуется отдельная единица идентификации СОМ для каждого типа экспортируемого интерфейса, который он предполагает поддерживать. Одна из методик реализации ConnectionPoint состоит в использовании того варианта методики вложения класса/композиции, которая учитывает различия в отношениях тождественности: class Surfboard : public ISurfboard, public IHazardousDevice, public ISharkBait, public IConnectionPointContainer { LONG m_cRef; // СОM reference count // счетчик ссылок СОМ // Surfboards don't support multiple outbound interfaces // of a given type, so it simply declares single pointers // of each possible type of callback interface // Surfboard не поддерживает несколько экспортируемых // интерфейсов заданного типа, поэтому он просто // объявляет одиночные указатели каждого возможного // типа интерфейса обратного вызова IShutdownNotify *m_pShutdownNotify; ISurfboardUser *m_pSurfer; // to deal with identity relationship of IConnectionPoint, // define an IShutdownNotify-specific nested class + member // для работы с отношением тождественности // IConnectionPoint, определяем специфический для // IShutdownNotify вложенный класс+член class XCPShutdownNotify : public IConnectionPoint { Surfboard *This(void); // use fixed offset // испопьзуем постоянное смещение // IUnknown methods... // методы IUnknown... // IConnectionPoint methods... // методы IConnectionPoint... } m_xcpShutdownNotify; // define an ISurfboardUser-specific nested class + member // определяем специфический для IShutdownNotify вложенный класс+член class XCPSurfboardUser : public IConnectionPoint { Surfboard *This(void); // use fixed offset // используем постоянное смещение // IUnknown methods... // методы IUnknown... // IConnectionPoint methods... // методы IConnectionPoint... } m_xcpSurfboardUser; // IUnknown methods... // методы IUnknown... // ISurfboard methods... // методы ISurfboard... // IHazardousDevice methods... // методы IHazardousDevice... // ISharkBait methods... // методы ISharkBait... // IConnectionPointContainer methods... // методы IConnectionPointContainer... }; Следует указать, что экземпляры класса Surfboard будут иметь две отдельные реализации IConnectionPoint, одна из которых используется для присоединения интерфейсов обратного вызова IShutdownNotify, а вторая – для присоединения интерфейсов ISurfboardUser. Эти две реализации разделены на отдельные классы C++, что позволяет каждой реализации IConnectionPoint иметь свои собственные уникальные реализации IUnknown и IConnectionPoint. В частности, может иметься три отдельных реализации QueryInterface со своими собственными наборами интерфейсных указателей, которые могут быть выделены для создания трех отдельных СОМ-копий. Из приведенного выше определения класса следует такая QueryInterface-peaлизация основного класса Surfboard: STDMETHODIMP Surfboard::QueryInterface(REFIID riid, void**ppv) { if (riid == IID_IUnknown || riid == IID_ISurfboard) *ppv = static_cast<ISurfboard*>(this); else if (riid == IID_IHazardousDevice) *ppv = static_cast< IHazardousDevice *>(this); else if (riid == IID_ISharkBait) *ppv = static_cast<ISharkBait *>(this); else if (riid == IID_IConnectionPointContainer) *ppv = static_cast<IConnectionPointContainer *>(this); else return (*ppv = 0), E_NOINTERFACE; ((IUnknown*)*ppv)->AddRef(); return S_OK; } Отметим, что доступ к интерфейсу IConnectionPoint не может быть осуществлен через эту главную реализацию QueryInterface. Каждый из методов QueryInterface вложенного класса будет выглядеть примерно так: STDMETHODIMP Surfboard::XCPShutdownNotify::QueryInterface(REFIID riid, void**ppv) { if (riid == IID_IUnknown || riid == IID_IConnectionPoint) *ppv = static_cast<IConnectionPoint *>(this); else return (*ppv = 0), E_NOINTERFACE; ((IUnknown*)*ppv)->AddRef(); return S_OK; } Эту же реализацию можно было бы применить и к классу XCPSurfboardUser. Между объектом Surfboard и двумя подобъектами, которые реализуют интерфейс IConnectionPoint не существует идентичности. Для того чтобы объект Surfboard не уничтожил себя раньше времени, подобъекты администратора соединений просто делегируют вызовы своих методов AddRef и Release в содержащий их объект surfboard: STDMETHODIMP_(ULONG) Surfboard::XCPShutdownNotify::AddRef(void) { return This()->AddRef(); /* AddRef containing object */ /* AddRef объекта-контейнера */ } STDMETHODIMP_(ULONG) Surfboard::XCPShutdownNotify::Release(void) { return This()->Release(); /* Release containing object */ /* Release объекта-контейнера */ } В приведенных выше методах предполагается, что метод This возвращает указатель на объект-контейнер Surfboard, используя вычисление некоторого постоянного смещения. Клиенты находят интерфейсы объекта IConnectionPoint посредством вызова метода объекта FindConnectionPoint, который для класса Surfboard мог бы выглядеть примерно так: STDMETHODIMP Surfboard::FindConnectionPoint(REFIID riid, IConnectionPoint **ppcp) { if (riid == IID_IShutdownNotify) *ppcp = IID_IShutdownNotify; else if (riid == IID_ISurfboardUser) *ppcp = &m_xcpSurfboardUser; else return (*ppcp = 0), CONNECT_E_NOCONNECTION; (*ppcp)->AddRef(); return S_OK; } Отметим, что объект выдает интерфейсные указатели IConnectionPoint только при запросе тех интерфейсов, на которые он сможет сделать обратный запрос. Необходимо указать также на поразительное сходство с большинством реализации QueryInterface. Основное различие состоит в том, что QueryInterface имеет дело с импортируемыми (inbound) интерфейсами, в то время как FindConnectionPoint – с экспортируемыми (outbound) интерфейсами. Поскольку метод IConnectionPoint::Advise принимает только интерфейс IUnknown, статически типизированный как интерфейсный указатель обратного вызова[1], то реализации Advise должны использовать QueryInterface для того, чтобы привязать указатель обратного вызова к соответствующему типу интерфейса: STDMETHODIMP Surfboard::XCPShutdownNotify::Advise(IUnknown *pUnk, DWORD *pdwCookie) { assert (pdwCookie && pUnk); *pdwCookie = 0; if (This()->m_pShutdownNotify) // already have one // уже имеем один return CONNECT_E_ADVISELIMIT; // QueryInterface for correct callback type // QueryInterface для корректирования типа обратного вызова HRESULT hr = pUnk->QueryInterface(IID_IShutdownNotify, (void**)&(This()->m_pShutdownNotify)); if (hr == E_NOINTERFACE) hr = CONNECT_E_NOCONNECTION; if (SUCCEEDED(hr)) // make up a meaningful cookie // готовим значимый маркер *pdwCookie = DWORD(This()->m_pShutdownNotify); return hr; } Напомним, что QueryInterface неявно вызывает AddRef, что означает следующее: объект Surfboard теперь хранит ссылку обратного вызова, причем она остается легальной за пределами области действия метода Advise. Отметим также, что если объект обратного вызова не реализует соответствующий интерфейс, то результирующий HRESULT преобразуется в CONNECT_E_NOCONNECTION. Если же сбой QueryInterface последовал по какой-либо иной причине, то HRESULT от QueryInterface передается вызывающей программе[2]. Основанный на приведенной выше реализации Advise соответствующий метод Unadvise имеет следующий вид: STDMETHODIMP Surfboard::XCPShutdownNotify::Unadvise(DWORD dwCookie) { // ensure that the cookie corresponds to a valid connection // убеждаемся, что маркер соответствует допустимому соединению if (DWORD (This()->m_pShutdownNotify) != dwCookie) return CONNECT_E_NOCONNECTION; // release the connection // освобождаем соединение This()->m_pShutdownNotify->Release(); This()->m_pShutdownNotify = 0; return S_OK; } В интерфейсе IConnectionPoint имеется три дополнительных вспомогательных метода, два из которых реализуются тривиально: STDMETHODIMP Surfboard::XCPShutdownNotify::GetConnectionInterface( IID *piid) { assert (piid); // return IID of the interface managed by this subobject // возвращаем IID интерфейса, управляемого этим подобъектом *piid = IID_IShutdownNofify; return S_OK; } STDMETHODIMP Surfboard::XCPShutdownNotify::GetConnectionPointContainer( IConnectionPointContainer **ppcpc) { assert(ppcpc); (*ppcpc = This())->AddRef(); // return containing object // возвращаем объект-контейнер return S_OK; } Последний из этих трех методов, EnumConnections, позволяет вызывающим программам перенумеровывать соединенные интерфейсы. Данный метод является дополнительным, так что реализации могут законно возвращать E_NOTIMPL. Для объявления о том, какие из экспортируемых интерфейсов класс реализации поддерживает, в IDL предусмотрен атрибут [source]: [uuid(315BC280-DEA7-11d0-8C5E-0080C73925BA) ] coclass Surfboard { [default] interface ISurfboard; interface IHazardousDevice; interface ISharkBait; [source] interface IShutdownNotify; [source, default] interface ISurfboardUser; } Кроме этого, в СОМ предусмотрено два интерфейса, которые позволяют средам этапа выполнения запрашивать объект самостоятельно (introspectively) возвращать информацию об импортируемых в него и экспортируемых им типах интерфейсов: [object,uuid(B196B283-BAB4-101A-B69C-00AA00341D07) ] interface IProvideClassInfo : Unknown { // return description of object's coclass // возвращаем описание кокласса объекта HRESULT GetClassInfo([out] ITypeInfo ** ppTI); } [object, uuid(A6BC3AC0-DBAA-11CE-9DE3-00M004BB851) ] interface IProvideClassInfo2 : IProvideClassInfo { typedef enum tagGUIDKIND { GUIDKIND_DEFAULT_SOURCE_DISP_IID = 1 } GUIDKIND; // return IID of default outbound dispinterface // возвращаем IID принятого по умолчанию экспортируемого диспинтерфейса HRESULT GetGUID([in] DWORD dwGuidKind, [out] GUID * pGUID); } Оба этих интерфейса весьма просты для реализации: STDMETHODIMP Surfboard::GetClassInfo(ITypeInfo **ppti) { assert(ppti != 0); ITypeLib *ptl = 0; HRESULT hr = LoadRegTypeLib(LIBID_BeachLib, 1, 0, 0, &ptl); if (SUCCEEDED(hr)) { hr = ptl->GetTypeInfoOfGuid(CLSID_Surfboard, ppti); ptl->Release(); } return hr; } STDMETHODIMP Surfboard::GetGUID (DWORD dwKind, GUID *pguid) { if (dwKind != GUIDKIND_DEFAULT_SOURCE_DISP_IID || !pguid) return E_INVALIDARG; // ISurfboardUser must be defined as a dispinterface // ISurfboardUser должен быть определен как диспинтерфейс *pguid = IID_ISurfboardUser; return S_OK; } Хотя экспортируемые интерфейсы не должны быть обязательно диспетчерскими интерфейсами (диспинтерфейсами), но ряд сред сценариев требуют этого, чтобы осуществлять естественное преобразование обратных вызовов в текст сценария. Предположим, что интерфейс ISurfboardUser определен как диспинтерфейс следующим образом: [uuid(315BC28A-DEA7-11d0-8C5E-0080C73925BA)] dispinterface ISurfboardUser { methods: [id(1)] void OnTiltingForward( [in] long nAmount); [id(2)] void OnTiltingSideways( [in] long nAmount); } При программировании на Visual Basic можно объявить переменные, понимающие тип интерфейса обратного вызова, принятый по умолчанию, таким образом: Dim WithEvents sb as Surfboard Наличие такого описания переменной дает программистам на Visual Basic возможность писать обработчики событий. Обработчики событий – это функции или подпрограммы, использующие соглашение VariableName_EventName. Например, для обработки события обратного вызова ОпТiltingForward на определенную выше переменную sb программисту Visual Basic пришлось бы написать следующий код: Sub sb_OnTiltingForward(ByVal nAmount as Long) MsgBox «The surfboard just tilted forward» End Sub Виртуальная машина Visual Basic будет действительно на лету обрабатывать реализацию ISurfboardUser, преобразуя поступающие вызовы методов в соответствующие определенные пользователем подпрограммы. Совмещение имен в IDLЧасто бывает необходимо объединить традиционные (старые) типы данных и идиомы программирования в одну систему на основе СОМ. В идеале существует простое и очевидное преобразование традиционного кода в его аналог, совместимый с IDL. Если у нас именно такой случай, то тогда переход к СОМ будет достаточно простым. Существуют, однако, ситуации, когда традиционные типы данных или идиомы приложения просто не могут разумным образом преобразовываться в IDL. Для решения этой проблемы в IDL предусмотрено несколько технологий замещения (aliasing techniques ), которые позволяют разработчику интерфейса составлять подпрограммы преобразования, способные переводить традиционные типы данных и идиомы в легальные, доступные для вызова представления на IDL. Прекрасным примером ситуации, в которой данная технология полезна, является идиома IEnum . Идиома нумератора СОМ была разработана раньше, чем компилятор IDL, поддерживаемый СОМ. Это означает, что первый разработчик интерфейса IEnum не мог проверить свою разработку на соответствие известным правилам преобразования в IDL. Метод перечислителя Next не может быть чисто преобразован в IDL[1]. Рассмотрим идеальный IDL-прототип метода Next: HRESULT Next([in] ULONG cElems, [out, size_is(cElems), length_is(*pcFetched)] double *prg, [out] ULONG *pcFetched); К сожалению, исходное «до-IDL-овское» определение метода Next устанавливало, что вызывающие программы могут передавать в качестве третьего параметра нулевой указатель, при условии, что первый параметр показывал, что запрашивается только один элемент. Это предоставляло вызывающим программам удобную возможность извлекать по одному элементу за раз: double dblElem; hr = p->Next(1, &dblElem, 0); Данное допустимое использование интерфейса противоречит приведенному выше IDL-определению, так как [out] -параметры самого верхнего уровня не имеют права быть нулевыми (нет места, куда интерфейсный заместитель мог бы сохранять результат). Для разрешения этого противоречия каждое определение метода Next должно использовать атрибут [call_as] для замены вызываемой формы (callable form) метода его отправляемой формой (remotable form). Атрибут [call_as] позволяет разработчику интерфейса выразить один и тот же метод в двух формах. Вызываемая форма метода должна использовать атрибут [local] для подавления генерирования маршалирующего кода. В этом варианте метода согласовывается, какие клиенты будут вызывать и какие объекты – реализовать. Отправляемая форма метода должна использовать атрибут [call_as] для связывания генерируемого маршалера с соответствующим методом в интерфейсной заглушке. Этот вариант метода описывает отправляемую форму интерфейса и должен использовать стандартные структуры IDL для описания запроса и ответных сообщений, необходимых для отзыва метода. Применяя технологию [call_as] к методу Next, получим такой IDL-код: interface IEnumDoubIe : IUnknown { // this method is what the caller and object see // данный метод, как его видят вызывающая программа и объект [local] HRESULT Next([in] ULONG cElems, [out] double *prgElems, [out] ULONG *pcFetched); // this method is how it goes out on the wire // данный метод, как он выходит на передачу [call_as(Next)] HRESULT RemoteNext([in] ULONG cElems, [out, size_is(cElems), length_is(*pcFetched)] double *prg, [out] ULONG *pcFetched); HRESULT Skip([in] ULONG cElems); HRESULT Reset(void); HRESULT Clone([out] IEnumDouble **ppe); } Результирующий заголовочный файл C/C++ будет содержать определение интерфейса, включающее в себя метод Next, но не определение метода RemoteNext. Что касается клиента и объекта, то у них нет метода RemoteNext. Он существует только для того, чтобы интерфейсный маршалер мог правильно отправить метод. Хотя у методов Next и RemoteNext списки параметров идентичны, при использовании данной технологии этого не требуется. На самом деле иногда бывает полезно включить в отправляемую форму метода добавочные параметры, чтобы дать исчерпывающее определение тому, как эта операция будет отправлена. С добавлением в метод пары атрибутов [local]/[call_as] исходный код, сгенерированный интерфейсным маршалером, более не сможет успешно компоноваться из-за непреобразованных внешних символов. Дело в том, что в этом случае разработчик интерфейса должен предусмотреть две дополнительных подпрограммы. Одна из них будет использоваться интерфейсным заместителем для преобразования формы метода с атрибутом [local] в форму с атрибутом [call_as]. B случае приведенного выше определения интерфейса компилятор IDL будет ожидать, что разработчик интерфейса обеспечит его следующей функцией: HRESULT STDMETHODCALLTYPE IEnumDouble_Next_Proxy(IEnumDouble *This, ULONG cElems, double *prg, ULONG *pcFetched); Вторая необходимая подпрограмма используется интерфейсной заглушкой для преобразования формы метода с атрибутом [call_as] в форму с атрибутом [local]. В случае приведенного выше определения интерфейса компилятор IDL будет ожидать от разработчика интерфейса следующей функции: HRESULT STDMETHODCALLTYPE IEnumDouble_Next_Stub(IEnumDouble *This, ULONG cElems, double *prg, ULONG *pcFetched); Для удобства прототипы для этих двух подпрограмм будут приведены в сгенерированном заголовочном файле C/C++. Как показано на рис. 7.10, определяемая пользователем подпрограмма [local]-to-[call_as] используется для заполнения таблицы vtbl интерфейсного заместителя и вызывается клиентом. Данная подпрограмма предназначена для преобразования вызова в удаленный вызов процедуры посредством вызова отправляемой версии, которая генерируется компилятором IDL. Для подпрограммы нумератора Next необходимо только убедиться, что в качестве третьего параметра передается ненулевой указатель: 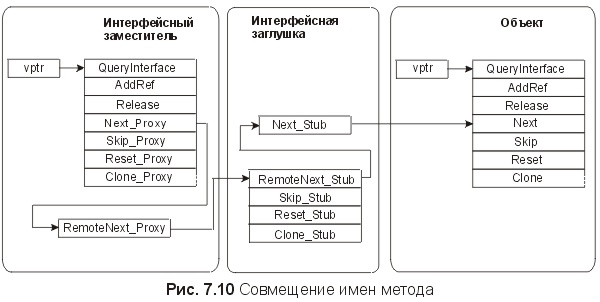 HRESULT STDMETHODCALLTYPE IEnumDouble_Next_Proxy( IEnumDouble *This, ULONG cElems, double *prg, ULONG *pcFetched) { // enforce semantics on client-side // осуществляем семантику на стороне клиента if (pcFetched == 0 && cElems != 1) return E_INVALIDARG; // provide a location for last [out] param // обеспечиваем место для последнего [out]-параметра ULONG cFetched; if (pcFetched == 0) pcFetched = &cFetched; // call remote method with non-null pointer as last param // вызываем удаленный метод с ненулевым указателем // в качестве последнего параметра return IEnumDouble_RemoteNext_Proxy(This, cElems, prg, pcFetched); } Отметим, что во всех случаях отправляемая версия метода получает в качестве последнего параметра ненулевой указатель. Определяемая пользователем подпрограмма [local]-to-[call_as] будет вызываться интерфейсной заглушкой после демаршалинга отправляемой формы метода. Эта подпрограмма предназначена для преобразования отправляемой формы вызова в локальный вызов процедуры на текущий объект. Поскольку реализации объекта иногда проявляют небрежность и не считают нужным показывать, сколько элементов возвращается при возвращении S_OK, правильность установки этого параметра обеспечивает подпрограмма преобразования со стороны объекта: HRESULT STDMETHODCALLTYPE IEnumDouble_Next_Stub( IEnumDouble *This, ULONG cElems, double *prg, ULONG *pcFetched) { // call method on actual object // вызываем метод на текущий объект HRESULT hr = This->Next(cElems, prg, pcFetched); // enforce semantics on object-side // проводим в жизнь семантику на стороне объекта if (hr == S_OK) // S_OK implies all elements sent // S_OK означает, что все элементы посланы *pcFetched = cElems; // [length_is] must be explicit // атрибут [length_is] должен быть явным return hr; } Интерфейсная заглушка всегда будет вызывать данную подпрограмму с ненулевым последним параметром. Технология с атрибутом [call_as] является полезной при организации преобразований из вызываемой формы в отправляемую по схеме «метод-за-методом». В СОМ также предусмотрена возможность специфицировать определяемые пользователем преобразования для отдельных типов данных при помощью атрибутов определения типов [transmit_as] и [wire_marshal]. Эти три технологии не следует считать основными при разработке интерфейсов; они существуют в основном для поддержки традиционных идиом и типов данных. Еще одним приемом, которым владеет компилятор IDL, является cpp_quote. Ключевое слово cpp_quote разрешает появление в IDL-файле любых операторов C/C++, даже если этот оператор не является допустимым в IDL. Рассмотрим следующее простейшее применение cpp_quote для внедрения определения встраиваемой функции в сгенерированный IDL заголовочный файл: // surfboard.idl cpp_quote(«static void Exit(void) { ExitProcess(1); }») Имея данный IDL-код, сгенерированный C/C++ заголовочный файл будет просто содержать следующий фрагмент: // surfboard.h static void Exit(void) { ExitProcess(1); } Ключевое слово cpp_quote может быть использовано для осуществления различных трюков в компиляторе IDL. Примером этого может служить тип данных REFIID . Фактическим определением IDL для этого типа является typedef IID *REFIID; В то же время тип C++ определен как typedef const IID& REFIID; Однако ссылки в стиле C++ не допускаются в IDL. Для решения данной проблемы системный IDL-файл использует следующий прием: // from wtypes.idl (approx.) // из файла wtypes.idl (приблизительно) cpp_quote(«#if 0») typedef IID "REFIID; // this is the pure IDL definition // это чисто IDL-определение cpp_quote(«#endif») cpp_quote(«#ifdef _cplusplus») cpp_quote(«#define REFIID const IID&») // C++ definition // определение C++ cpp_quote(«#else») cpp_quote(«#define REFIID const IID * const») // С definition // определение С cpp_quote(«#endif») Результирующий заголовочный файл C++ выглядит так: // from wtypes.h (approx.) // из файла wtypes.h (приблизительно) #if 0 typedef IID *REFIID; #endif #ifdef _cplusplus #define REFIID const IID& #else #define REFIID const IID * const #endif Этот несколько гротескный прием необходим, поскольку многие базовые интерфейсы СОМ были определены без учета возможного применения IDL. Асинхронные методыВызовы методов в СОМ являются по умолчанию синхронными. Это означает, что клиентский поток заблокирован до тех пор, пока ответное ORPC-сообщение не получено и не демаршалировано. Такая схема в полной мере демонстрирует, как работает обычный вызов метода в одном потоке (same-thread), и это с полным основанием принято по умолчанию. До появления Windows NT 5.0 не было способа осуществить вызов метода и продолжать обработку одновременно с выполнением метода без явного порождения дополнительных потоков. В версии СОМ Windows NT 5.0 вводится поддержка асинхронного вызова метода. Асинхронность является свойством метода и должна быть выражена в IDL посредством применения атрибута [async_uuid]. Детали этой технологии во время написания данного текста находились в процессе непрерывного изменения. За подробностями обращайтесь к соответствующей документации. Где мы находимся?В данной главе обсуждался ряд тем, относящихся к разработке и использованию интерфейсов СОМ. Хотя эта глава никоим образом не содержит исчерпывающего каталога полезных идиом разработки, в ней была сделана попытка решить несколько существенных вопросов, не обсуждавшихся в предшествующих главах книги. По мере того как мое собственное понимание СОМ развивалось в течение двух лет, потребовавшихся для написания этой книги, я пришел к убеждению, что разработчикам следовало бы уделять меньше внимания специфическим возможностям СОМ (таким, как точки стыковки, моникеры, диспетчерские интерфейсы), а вместо этого сосредоточиться на трех китах СОМ: интерфейсы, объекты классов, апартаменты. Вооруженный доскональным пониманием этих трех тем, я твердо верю, что нет вершин, которые нельзя было бы покорить с помощью СОМ. |
|
|||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
||||
|
|
||||